[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.10.08
📕 학습 목록
- 데이터베이스 유형
- SQL vs NoSQL
- MongoDB
- Redis
* 정규화 추가 설명 https://mangkyu.tistory.com/110
📗 기억할 내용
1. 데이터베이스 유형
1) 데이터베이스 유형
| 관계형/비관계형 | 데이터베이스 유형 | 대표 엔진 |
| RDBMS | Relational | Oracle, MySQL, PostgreSQL, Microsoft SQL Server, MariaDB |
| DBMS | Document | MongoDB, CouchDB |
| Key-value | Redis | |
| Column-family | Cassandra, HBase | |
| Search | Elastic | |
| Graph | Neo4j, OrientDB, ArangoDB |
2) 클라우드 데이터베이스
- AWS에서 제공하는 데이터베이스 : https://aws.amazon.com/ko/products/databases/?nc2=h_ql_prod_db_db
- GCP에서 제공하는 데이터베이스 : https://cloud.google.com/products/databases/
- Azure 에서 제공하는 데이터베이스 : https://azure.microsoft.com/ko-kr/products/category/databases
2. NoSQL
1) NoSQL이란?
- NoSQL(Not Only SQL) : 전통적인 관계형 데이터베이스 관리 시스템(RDBMS)과는 다른 방식으로 데이터를 저장하고 관리하는 데이터베이스 시스템(DBMS)을 의미
- SQL : RDBMS 에서 데이터를 다루는 언어
- NoSQL : 다양한 비관계형 데이터베이스 관리 시스템(DBMS)을 총칭 ('언어'를 의미하는게 X)
2) 특징
- 스키마가 없는 데이터 구조NoSQL 데이터베이스는 미리 정의된 스키마가 없거나 유연한 스키마를 사용함. 즉, 데이터를 저장할 때 각 데이터 항목이 다른 구조를 가질 수 있음. 이를 통해 데이터를 자유롭게 확장하거나 수정할 수 있어 유연성이 매우 높음
- 수평적 확장성: NoSQL 시스템은 데이터를 여러 서버에 분산시켜 저장하는 방식으로 설계되어 있어 대규모 데이터를 쉽게 처리할 수 있음. 새로운 데이터를 추가할 때 서버를 수평으로 확장하여 처리 성능을 유지할 수 있음
- 높은 성능: NoSQL은 주로 키-값 쌍, 문서, 그래프 등을 이용하여 데이터에 빠르게 접근할 수 있도록 설계됨. 특히 분산된 데이터 환경에서 읽기 및 쓰기 성능이 우수하며, 특정 응용 분야에 맞게 최적화된 구조를 가짐
- 트랜잭션 처리 대신 가용성 우선: 관계형 데이터베이스에서는 ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션을 엄격하게 준수하지만, NoSQL은 이러한 트랜잭션 성격보다는 가용성과 확장성을 더 중시하는 경향이 있음. 일관성(consistency)은 필요에 따라 유연하게 적용할 수 있음
3) NoSQL(DBMS)의 주요 유형
| NoSQL 유형 |
문서형 (Document) |
키-값 (Key-value) |
열 기반 (Column-family) |
검색형 (Search) |
그래프 (Graph) |
| 대표 엔진 | MongoDB, CouchDB |
Redis, DynamoDB |
Cassandra, HBase |
Elastic | Neo4j, ArangoDB |
| 저장 방식 | 데이터를 JSON, BSON 같은 형식으로 저장 | 데이터를 고유한 키와 그에 매핑된 값으로 저장 | 각 열이 독립적으로 저장되고 관리됨 | 역색인(Inverted Index) 구조를 사용해 저장; 문서에 포함된 단어들을 키로 하여, 해당 단어가 포함된 문서의 리스트를 값으로 저장 | 노드와 관계를 기반으로 데이터를 저장하고 처리 |
| 장점 | 문서 내에 키-값 쌍을 포함한 복잡한 데이터를 저장할 수 있음 | 단순한 구조의 데이터를 빠르게 읽고 쓸 수 있음 | 대규모 데이터를 효율적으로 처리할 수 있음 | 대규모 텍스트 데이터를 빠르게 검색하고 분석할 수 있 | 복잡한 관계형 쿼리를 쉽게 처리할 수 있음 |
| 적용 | 소셜 미디어, 콘텐츠 관리 시스템(CMS) | 캐시, 세션 관리, 실시간 데이터 분석 | 빅데이터 분석, 로그 데이터 저장 | 실시간 검색, 로그 분석 | 추천 시스템, 네트워크 분석 |
[tip] Relational vs. Document Database


4) NoSQL의 장∙단점
① 장점
- 유연성: 고정된 스키마 없이 데이터 구조를 저장할 수 있어, 다양한 형태의 데이터를 다룰 때 유리
- 확장성: 수평적 확장을 통해 대규모 데이터를 효율적으로 처리할 수 있음
- 고성능: 데이터 구조에 따라 빠른 읽기/쓰기 성능을 제공할 수 있음
- 대규모 분산 처리: 데이터를 여러 서버에 분산 저장하여 처리할 수 있어, 확장성과 가용성을 높일 수 있음
② 단점
- 일관성 문제: 관계형 데이터베이스의 ACID 트랜잭션 모델을 따르지 않기 때문에, 일관성 문제를 다룰 필요가 있음
- 복잡한 쿼리 처리의 제한: NoSQL은 SQL처럼 복잡한 조인이나 집계 연산을 기본적으로 지원하지 않거나 제한적일 수 있음
- 학습 곡선: 데이터베이스 유형에 따라 다른 API와 쿼리 방식을 사용하므로 학습이 필요할 수 있음
[tip] 수직 확장 vs 수평 확장
| 구분 | 수직 확장 (Scale up) | 수평 확장 (Scale out) NoSQL |
| 개념 | 단일 서버의 스펙을 더 좋은 것으로 업그레이드하는 방식 | 여러 대의 서버를 추가로 설치하여 여러 서버가 작업을 분담하는 방식 |
| 장점 | 비교적 간단하게 서버를 업그레이드할 수 있으며, 여러 서버를 관리할 필요가 없음 | - 무한대로 확장이 가능하며, 단일 장애점이 없어 장애에 치명적이지 않음 - 동시 작업 가능(병렬 처리); 부하 분산 |
| 단점 | 하드웨어의 한계로 인해 무한한 확장이 불가능하며, 업그레이드 시 다운타임이 발생할 수 있음 | 클러스터링 작업에 추가 비용 발생, 기술적·관리적으로 복잡하며, 네트워크 성능에 따라 한계가 존재할 수 있음 |
| 적용 | 데이터 일관성, 무결성이 중요한 데이터베이스 서버 | 웹 서비스, 이벤트성 서비스 등 가변적인 유저 수요를 처리해야 하는 경우 |
3. MongoDB
1) 정의
- MongoDB : NoSQL 데이터베이스의 일종으로, 문서 지향(Document-Oriented) 데이터베이스
- 관계형 데이터베이스처럼 테이블과 행을 사용하는 대신, MongoDB는 데이터를 JSON(BSON) 형식으로 문서(document)에 저장함
- 이 문서 지향 방식은 매우 유연하며, 비정형 데이터나 반정형 데이터를 처리하는 데 적합함
2) 특징
- 스키마리스(Schema-less) 구조
- MongoDB는 정해진 스키마가 없어 데이터를 유연하게 저장할 수 있음. 즉, 문서마다 다른 필드나 구조를 가질 수 있음
- 데이터가 빈번하게 변경되거나 새로운 필드가 추가될 수 있는 환경에서 매우 유용함
- JSON/BSON 형식 데이터 저장
- 데이터를 JSON 형식으로 저장하며, 실제로는 JSON의 이진 형태인 BSON(Binary JSON)으로 저장되어 더 빠른 데이터 처리 속도를 제공함
- 수평적 확장(Sharding)
- MongoDB는 데이터를 여러 서버에 분산하여 저장할 수 있는 샤딩(Sharding) 기능을 제공함. 이를 통해 대규모 데이터를 효과적으로 처리하고 확장할 수 있음
- 수평적 확장을 통해 성능과 용량을 유연하게 늘릴 수 있음
- 복제(Replication)와 고가용성
- MongoDB는 복제 세트(Replica Set) 기능을 통해 데이터의 복제본을 여러 서버에 저장함. 이는 장애 발생 시 다른 복제본에서 데이터를 읽어올 수 있도록 하여 데이터의 가용성을 높임
- 강력한 쿼리 언어
- MongoDB는 관계형 데이터베이스와 비슷한 방식으로 데이터를 조회할 수 있는 강력한 쿼리 언어를 제공함. 단순한 키-값 조회뿐만 아니라, 복잡한 검색, 필터링, 정렬, 집계 등의 기능을 제공함
- 트랜잭션 지원
- 최신 MongoDB 버전에서는 ACID 트랜잭션을 지원하여, 여러 문서에 걸친 트랜잭션을 안전하게 처리할 수 있음. 이를 통해 일관성 있는 데이터 처리가 가능함
3) 장∙단점
① 장점
- 유연성: 데이터 구조가 유연해 데이터 모델을 쉽게 변경할 수 있으며, 비정형 데이터 저장에 적합
- 확장성: 수평적 확장이 용이하여 대규모 분산 환경에서 데이터를 처리하는 데 효과적
- 성능: 높은 읽기/쓰기 성능을 제공하며, 빠른 개발과 배포를 지원
- 오픈소스: MongoDB는 오픈소스로 제공되며, 다양한 플랫폼에서 사용할 수 있음
② 단점
- 일관성 문제: 기본적으로 MongoDB는 가용성(Availability)과 파티션 허용(Partition Tolerance)에 집중하기 때문에, 트랜잭션 처리나 데이터 일관성이 중요한 시스템에서는 적합하지 않을 수 있음
- 관계형 데이터 처리의 어려움: 복잡한 관계형 데이터 모델을 구현하기에는 적합하지 않으며, 관계형 데이터베이스처럼 조인(join) 작업이 제한적임
4) MongoDB 실행
① 설치



② MongoDB 서버 실행
- 설치 경로 찾아 MongoDB 서버 실행 (mongod.exe : MongoDB의 데이터베이스 서버를 실행하는 명령어)
- 서버가 실행됐는지 확인법 1 : 웹 브라우저에 'localhost:27017' 검색 → 문구 확인
- 서버가 실행됐는지 확인법 2 : PowerShell에 'netstat -ano | select-string "27017"' 검색 후 → 문구 확인



③ 환경변수 추가
- 'bin' 폴더 경로 (C:\Program Files\MongoDB\Server\8.0\bin) 로 추가
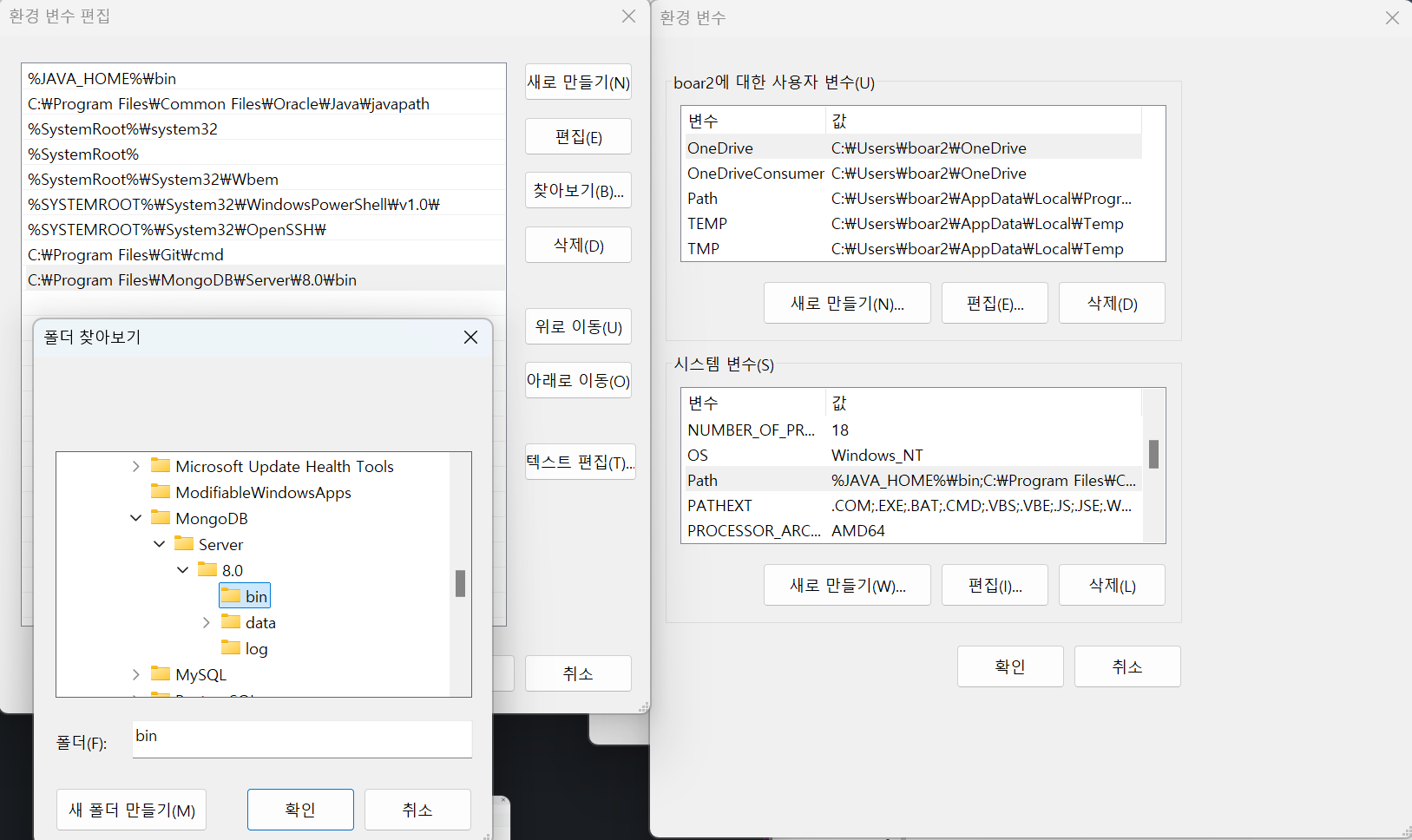
④ MongoDB Shell 실행
- MongoDB Compass 실행 → Add new connection → Open MongoDB Shell
- 서버 연결 에러 문구 발생시
# PoweShell에 명령어 입력
# 1. MongoDB 서버(mongod)가 실행 중인지 확인
netstat -ano | findstr 27017
# 2. 서버 실행
mongod --dbpath "C:\data\db"

5) VS Code 에서 MongoDB 연결하기
① 플러그인 설치
- MongoDB 관련 플러그인

- SQL, NoSQL 관련 플러그인


② MongoDB 연결
- 맨 아래 NoSQL 플러그인 클릭 → Create Connection → MongoDB 연결

③ MongoDB 보안 설정 변경 (비활성화)
- 관리자 권한으로 메모장 열기
- 관리자 권한으로 메모장을 열어야 시스템 파일이나 설정 파일을 수정할 수 있음. 보안 설정을 변경하려면 관리자 권한이 필요함
- mongod.cfg 파일 열기
- mongod.cfg는 MongoDB 서버 설정 파일임. 이 파일에는 MongoDB의 동작에 대한 여러 설정이 포함되어 있으며, 보안 설정을 포함한 서버 동작을 제어할 수 있음

- #security 항목 수정 : 주석(#) 제거 → 줄바꿈하여 스페이스바 두번(tab X) → 'authorization: disabled' 입력 → 저장
- security 항목은 MongoDB의 보안 및 인증 설정을 다루는 부분임. 이 항목을 수정하는 것은 MongoDB가 사용자 인증을 활성화할지 여부를 결정하는 것을 의미함
- 보통 MongoDB는 기본적으로 인증 기능이 비활성화(disabled)되어 있으며, 보안을 강화하려면 인증을 활성화(enabled)해야 함


④ MongoDB 정상 작동 확인
- MongoDB 서비스 상태 확인
- PowerShell 관리자 권한 열기
- PowerShell을 관리자 권한으로 실행해야 시스템 서비스를 제어할 수 있음. 특히, MongoDB와 같은 서버 서비스를 시작하거나 중지하는 작업은 관리자 권한이 필요함
- 명령어 입력
- PowerShell 관리자 권한 열기
# MongoDB가 현재 실행 중인지 중지된 상태인지 확인
Get-Service -Name Mongo*- MongoDB 서비스 중지
- 명령어 입력
net stop MongoDB- MongoDB 서비스 다시 시작
- 명령어 입력
net start MongoDB
⑤ MongoDB Compass Shell에서 user 생성

⑥ MongoDB 보안 설정 변경 (활성화)
- 메모장에서 'authorization: disabled' → 'authorization: enabled' 로 바꾸고, 저장
⑦ VS Code 에서 username('root'), pwd 입력하여 새로 연결

⑧ admin에서 Open Query

⑨ 쿼리문 입력

5) MongoDB 주요 쿼리 문법 (CRUD, 집계, 인덱스)
① 데이터 삽입 (Create)
- 단일 문서 삽입
- insertOne() 메서드 : 컬렉션에 단일 문서를 삽입
db.collection('users').insertOne({
name: "Alice",
age: 30,
status: "active"
});- 여러 문서 삽입
- insertMany() 메서드 : 컬렉션에 여러 문서를 한꺼번에 삽입
db.collection('inventory').insertMany([
{ item: "notebook", qty: 50, tags: ["office", "paper"], size: { h: 21, w: 29.7, uom: "cm" }},
{ item: "pen", qty: 100, tags: ["writing", "stationery"], size: { h: 14, w: 1.4, uom: "cm" }}
]);
② 데이터 조회 (Read)
- 전체 문서 조회
- find() 메서드 : 컬렉션의 모든 문서를 조회
- toArray() : 배열로 변환해 결과를 반환
db.collection('inventory').find({}).toArray();- 조건을 사용한 문서 조회
- MongoDB 쿼리는 JSON 객체 형식으로 조건을 지정해 문서를 조회
db.collection('inventory').find({ status: "A" }).toArray();- 비교 연산자
- $gt (greater than): 크다
- $lt (less than): 작다
- $gte (greater than or equal): 크거나 같다
- $lte (less than or equal): 작거나 같다
db.collection('inventory').find({ qty: { $gt: 50 } }).toArray();- 논리 연산자
- $or: 둘 중 하나의 조건을 만족
- $and: 두 조건을 모두 만족
// OR 조건: qty가 50 이상이거나 status가 "A"인 문서 조회
db.collection('inventory').find({ $or: [ { qty: { $gte: 50 } }, { status: "A" } ] }).toArray();
// AND 조건: status가 "A"이고 qty가 30 미만인 문서 조회
db.collection('inventory').find({ status: "A", qty: { $lt: 30 } }).toArray();- 배열 쿼리
- 배열 필드에 특정 값이 포함된 문서를 조회할 수 있음
- 배열에 있는 모든 값과 일치하는 문서를 찾으려면 $all 연산자를 사용
db.collection('inventory').find({ tags: "stationery" }).toArray();
db.collection('inventory').find({ tags: { $all: ["stationery", "writing"] } }).toArray();- 정렬, 제한, 스킵
- 정렬: sort() 메서드를 사용하여 결과를 정렬
- 제한: limit() 메서드를 사용하여 결과 개수를 제한
- 스킵: skip() 메서드를 사용하여 특정 개수의 문서를 건너뜀
db.collection('inventory').find({}).sort({ qty: -1 }).limit(10).skip(5).toArray();
③ 데이터 수정 (Update)
- 단일 문서 수정
- updateOne() 메서드 : 조건에 맞는 첫 번째 문서를 수정
db.collection('inventory').updateOne(
{ item: "pen" }, // 조건
{ $set: { qty: 60 } } // 수정할 값
);- 여러 문서 수정
- updateMany()메서드 : 조건에 맞는 모든 문서를 수정
db.collection('inventory').updateMany(
{ status: "A" }, // 조건
{ $set: { qty: 100 } } // 수정할 값
);- 연산자
- $set: 필드 값을 지정한 값으로 변경
- $inc: 지정된 값만큼 숫자 필드 값을 증가/감소
- $unset: 필드를 삭제
// 필드 값 증가
db.collection('inventory').updateOne(
{ item: "pen" },
{ $inc: { qty: 5 } }
);
// 필드 삭제
db.collection('inventory').updateOne(
{ item: "pen" },
{ $unset: { tags: "" } }
);
④ 데이터 삭제 (Delete)
- 단일 문서 삭제
- deleteOne() 메서드 : 조건에 맞는 첫 번째 문서를 삭제
db.collection('inventory').deleteOne({ item: "pen" });- 여러 문서 삭제
- deleteMany() 메서드 : 조건에 맞는 모든 문서를 삭제
db.collection('inventory').deleteMany({ status: "A" });
⑤ Aggregation (집계)
- Aggregation 파이프라인
- aggregate() 메서드 : 여러 단계의 집계를 통해 데이터를 처리. 여러 단계의 연산을 파이프라인으로 처리함
- 기본 연산자
- $match: 조건을 사용해 문서를 필터링
- $group: 데이터를 그룹화하여 결과를 집계
- $project: 특정 필드만 포함하거나 제외
db.collection('inventory').aggregate([
{ $match: { status: "A" } }, // 조건 필터링
{ $group: { _id: "$item", totalQty: { $sum: "$qty" } } }, // 그룹화 및 집계
{ $project: { item: 1, totalQty: 1 } } // 필요한 필드만 선택
]);
⑥ 인덱스(Index) 및 성능 최적화
- 인덱스 생성
- createIndex() 메서드 : 특정 필드에 인덱스를 생성하여 조회 성능을 높임
db.collection('inventory').createIndex({ item: 1 });- 인덱스 삭제
- dropIndex() 메서드 : 기존 인덱스를 삭제
db.collection('inventory').dropIndex("item_1");
4. Redis
1) 정의
- 오픈 소스 비관계형 데이터베이스
- 특히 메모리 기반의 데이터 구조 서버로 널리 사용됨; 데이터를 메모리에 저장하기 때문에 매우 빠른 성능을 자랑하며, 다양한 데이터 구조를 지원함
2) 특징
- 인메모리 데이터 저장: 데이터를 메모리에 저장하여 매우 빠른 읽기 및 쓰기 성능을 제공. 이를 통해 주로 캐시나 실시간 데이터 처리가 필요한 곳에서 많이 사용됨
- 데이터 구조 지원: 문자열(String), 리스트(List), 집합(Set), 해시(Hash), 정렬된 집합(Sorted Set) 등의 다양한 데이터 구조를 지원. 이를 통해 복잡한 데이터를 효율적으로 관리할 수 있음.
- 영구 저장 옵션: 기본적으로 메모리에 데이터를 저장하지만, 데이터를 디스크에 백업할 수 있는 기능(RDB, AOF)을 제공. 이를 통해 데이터를 영구적으로 보관하고 복구할 수 있음
- 복제 및 고가용성: Redis는 마스터-슬레이브 복제를 지원하며, 이를 통해 데이터를 여러 노드에 복사하여 가용성을 높이고 장애 복구 시간을 줄일 수 있음
- Pub/Sub 메시징 시스템: Redis는 퍼블리셔와 구독자 간의 메시징 시스템도 제공하여 실시간 알림이나 메시징 시스템으로 사용할 수 있음
- 트랜잭션: Redis는 기본적인 트랜잭션을 지원하여 여러 명령을 하나의 작업으로 묶어 처리할 수 있음
- 고성능: Redis는 CPU 성능을 최대한 활용할 수 있도록 싱글 스레드 방식으로 작동하며, 이를 통해 적은 자원으로 높은 성능을 낼 수 있음
3) 실행
① 설치



② redis-cli.exe 실행 : 서버와 상호작용하기위한 클라이언트 도구
- 데이터 조회 및 관리: Redis 데이터베이스에 저장된 데이터를 조회하거나 삽입, 수정, 삭제 등의 작업을 수행할 수 있음
- 명령어 실행: Redis 서버에 다양한 명령어를 보내 실시간으로 동작을 테스트하거나 특정 설정을 변경할 수 있음
- 서버 상태 확인: INFO, PING 등의 명령을 사용해 서버의 상태나 성능을 확인할 수 있음


③ VS Code 에 Redis 연결
- Add Connection 클릭 → Redis 선택 후 Connect 하기


- Open Terminal 클릭 → 아까랑 똑같이 ping 입력시 PONG 반환됨

- set 만 입력해도 명령어 입력 가이드 뜸

④ 쿼리 입력 후 리스트 확인
- set "key" value 입력 → 새로운 key 리스트 생성 → View Key Detail


4) Redis 주요 쿼리 문법
① 기본 구조; Redis는 키-값(key-value) 형태의 데이터 저장소로, 데이터를 매우 빠르게 처리할 수 있는 인메모리 데이터
- COMMAND: Redis에서 실행할 명령어
- key: 명령어를 실행할 대상 키
- arguments: 필요에 따라 추가로 제공하는 인수
COMMAND key [arguments]
② 주요 데이터 타입 관련 명령어; Redis는 다양한 데이터 타입을 지원하며, 각 타입에 따라 명령어가 다름
- String (문자열)
- SET : 문자열 값을 설정
- GET : 설정된 문자열 값을 조회
- INCR / DECR : 문자열 값을 정수로 간주하고, 증가 / 감소
/* SET */
SET key value
/* GET */
GET key
/* INCR / DECR */
INCR key
DECR key
- Hash (해시)
- HSET : 해시 필드와 값을 설정
- HGET : 특정 필드의 값을 조회
- HGETALL : 해시 내 모든 필드와 값을 조회
/* HSET */
HSET key field value
/* HGET */
HGET key field
/* HGETALL */
HGETALL key- List (리스트)
- LPUSH / RPUSH : 리스트의 왼쪽 / 오른쪽에 값 추가
- LPOP / RPOP : 리스트의 왼쪽 / 오른쪽에서 값 제거
- LRANGE : 리스트의 특정 범위의 값을 조회
/* LPUSH / RPUSH */
LPUSH key value1 value2 ...
RPUSH key value1 value2 ...
/* LPOP / RPOP */
LPOP key
RPOP key
/* LRANGE */
LRANGE key start stop- Set (집합)
- SADD : 집합에 값 추가
- SMEMBERS : 집합 내 모든값 조회
- SISMEMBER : 특정 값이 집합에 존재하는지 확인
/* SADD */
SADD key member1 member2 ...
/* SMEMBERS */
SMEMBERS key
/* SISMEMBER */
SISMEMBER key member- Sorted Set (정렬된 집합)
- ZADD : 정렬된 집합에 값 추가. 추가할 때 점수(정렬 기준)도 함께 설정
- ZRANGE : 특정 범위의 값을 조회
- ZREM : 정렬된 집합에서 특정 값을 제거
/* ZADD */
ZADD key score1 member1 score2 member2 ...
/* ZRANGE */
ZRANGE key start stop
/* ZREM */
ZREM key member
③ 키 관련 명령어
- DEL : 특정 키 삭제
- EXISTS : 특정 키가 존재하는지 확인
- EXPIRE : 특정 키에 TTL(유효시간) 설정
/* DEL */
DEL key
/* EXISTS */
EXISTS key
/* EXPIRE */
EXPIRE key seconds
④ 트랜잭션; Redis에서 트랜잭션은 여러 명령어를 순차적으로 처리할 수 있는기능을 제공함
- MULTI : 트랜잭션 시작
- EXEC : 트랜잭션 실행
- DISCARD : 트랜잭션 취소
⑤ 기타 명령어
- PING : Redis 서버가 실행 중인지 확인
- INFO : 서버의 상태 정보를 조회
📘 쿼리 실습
1. MongoDB 쿼리문 작성
1) 기본 CRUD 작업
① Create (데이터 삽입)
// users 컬렉션에 단일 문서 삽입 db('thing').collection('users').insertOne( { name: "sue", age: 26, status: "pending" } ); // inventory 컬렉션에 단일 문서 삽입 db('thing').collection('inventory').insertOne( { item: 'canvas', qty: 100, tags: ['cotton'], size: { h: 28, w: 35.5, uom: 'cm' } } ); // inventory 컬렉션에 여러 문서 삽입 db('thing').collection('inventory').insertMany([ { item: 'journal', qty: 25, tags: ['blank', 'red'], size: { h: 14, w: 21, uom: 'cm' } }, { item: 'mat', qty: 85, tags: ['gray'], size: { h: 27.9, w: 35.5, uom: 'cm' } }, { item: 'mousepad', qty: 25, tags: ['gel', 'blue'], size: { h: 19, w: 22.85, uom: 'cm' } } ]);
② Read (데이터 조회)// 모든 문서 조회 db('thing').collection('inventory').find({}).toArray(); // 조건에 따른 문서 조회 db('thing').collection('users').find({ name: "sue" }).toArray();
2) 조건부 쿼리
① 동등성 조건 조회
// 특정 필드 값으로 조회 (status: "D") db('thing').collection('inventory').find( { status: "D" } ).toArray(); // 여러 값 중 하나를 갖는 문서 조회 (status가 "A" 또는 "D") db('thing').collection('inventory').find( { status: { $in: [ "A", "D" ] } } ).toArray();
② 논리 연산자 사용
// AND 조건 (status가 "A"이고, qty가 30 미만인 문서) db('thing').collection('inventory').find( { status: "A", qty: { $lt: 30 } } ).toArray(); // OR 조건 (status가 "A"이거나, qty가 30 미만인 문서) db('thing').collection('inventory').find( { $or: [ { status: "A" }, { qty: { $lt: 30 } } ] } ).toArray(); // AND 및 OR 조건 혼합 (status가 "A"이고, qty가 30 미만이거나, item이 "p"로 시작하는 문서) db('thing').collection('inventory').find( { status: "A", $or: [ { qty: { $lt: 30 } }, { item: /^p/ } ] } ).toArray();
3) 중첩된 문서 쿼리
① 중첩된 필드 쿼리
// 중첩된 필드 값 조회 (size.uom이 "in"인 문서) db('thing').collection('inventory').find( { "size.uom": "in" } ).toArray(); // 중첩된 필드 값의 조건 조회 (size.h가 15 미만인 문서) db('thing').collection('inventory').find( { "size.h": { $lt: 15 } } ).toArray();
② 중첩 문서와 배열 필드 쿼리
// 배열 필드에서 조건 조회 (instock 필드의 qty 값이 20 이하인 문서) db('thing').collection('inventory').find( { 'instock.qty': { $lte: 20 } } ).toArray(); // 배열 인덱스 위치로 요소 쿼리 (dim_cm 배열의 두 번째 값이 25보다 큰 문서) db('thing').collection('inventory').find( { "dim_cm.1": { $gt: 25 } } ).toArray();
4) 애그리게이션(Aggregation) 쿼리
① updateOne 사용한 업데이트
// 애그리게이션 파이프라인을 사용한 문서 업데이트 db('thing').collection('students').updateOne( { _id: 3 }, [ { $set: { "test3": 98, modified: "$$NOW"} } ] );
② updateMany 사용한 여러 문서 업데이트
// 필드 표준화 및 modified 필드 업데이트 db('thing').collection('students2').updateMany( {}, [ { $replaceRoot: { newRoot: { $mergeObjects: [ { quiz1: 0, quiz2: 0, test1: 0, test2: 0 }, "$$ROOT" ] } } }, { $set: { modified: "$$NOW"} } ] );
5) 문서 삭제
① deleteMany 사용
// 모든 문서 삭제 db('thing').collection('inventory').deleteMany({}); // 조건에 맞는 문서 삭제 (status가 "A"인 모든 문서) db('thing').collection('inventory').deleteMany({ status: "A" });
② deleteOne 사용
// 조건에 맞는 단일 문서 삭제 (status가 "D"인 문서) db('thing').collection('inventory').deleteOne( { status: "D" } );
📙 내일 일정
- DBeaver 실습

'TIL _Today I Learned > 2024.10' 카테고리의 다른 글
| [DAY 59] 자연어 처리 (NLP) (2) | 2024.10.14 |
|---|---|
| [DAY 58] 자연어 처리 (NLP) (1) | 2024.10.11 |
| [DAY 57] SQL 실습 (0) | 2024.10.10 |
| [DAY 55] SQL의 응용 (1) | 2024.10.07 |
| [DAY 54] SQL의 응용 (2) | 2024.10.02 |



