[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.10.07
📕 학습 목록
- PostgreSQL
- DBeaver
- TCL 명령어
- ERD
- 테이블 생성
- 데이터 소스 vs 데이터베이스 vs 데이터 스키마 vs 테이블
- 정규화
* 정규화 추가 설명 https://mangkyu.tistory.com/110
📗 기억할 내용
1. PostgreSQL
1) PostgreSQL?
- PostgreSQL : 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)
- 고성능, 안정성 및 확장성을 갖춘 관계형 데이터베이스 관리 시스템으로, 다양한 데이터 처리 요구를 충족할 수 있는 기능을 제공


2) psql
- 정의
- psql : PostgreSQL 데이터베이스를 관리하기 위한 명령줄 인터페이스(CLI) 도구
- SQL 쿼리 실행, 데이터베이스 관리, 스크립트 실행 등을 통해 효율적으로 PostgreSQL 데이터베이스를 관리할 수 있음
- psql 실행
① 윈도우 검색창에 psql 검색 → enter & 비밀번호 입력
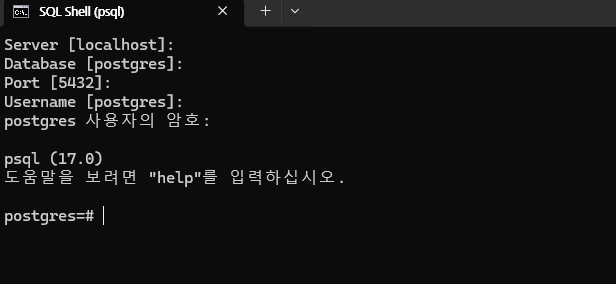
② SQL 쿼리 실행
- 테이블 조회
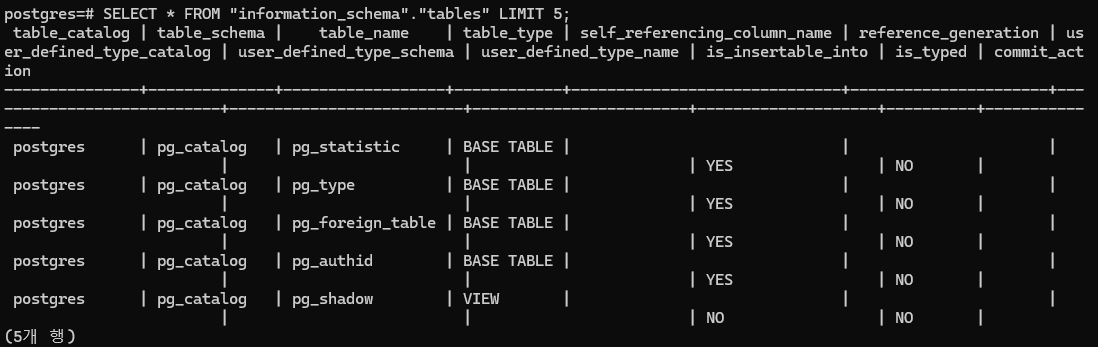
- 데이터베이스 생성

- 현존하는 데이터베이스 목록 확인 (\list)

3) pgAdmin 4
- 정의
- pgAdmin 4 : PostgreSQL 데이터베이스를 관리하고 개발하기 위한 GUI 도구로, 사용자가 데이터베이스와 상호작용할 수 있는 다양한 기능을 제공
- 직관적인 웹 기반 인터페이스와 SQL 편집기를 통해 효율적으로 데이터베이스 작업을 수행할 수 있음
- pgAdmin 4 실행
① 왼쪽의 Servers 클릭 → 입력창에 비밀번호 입력
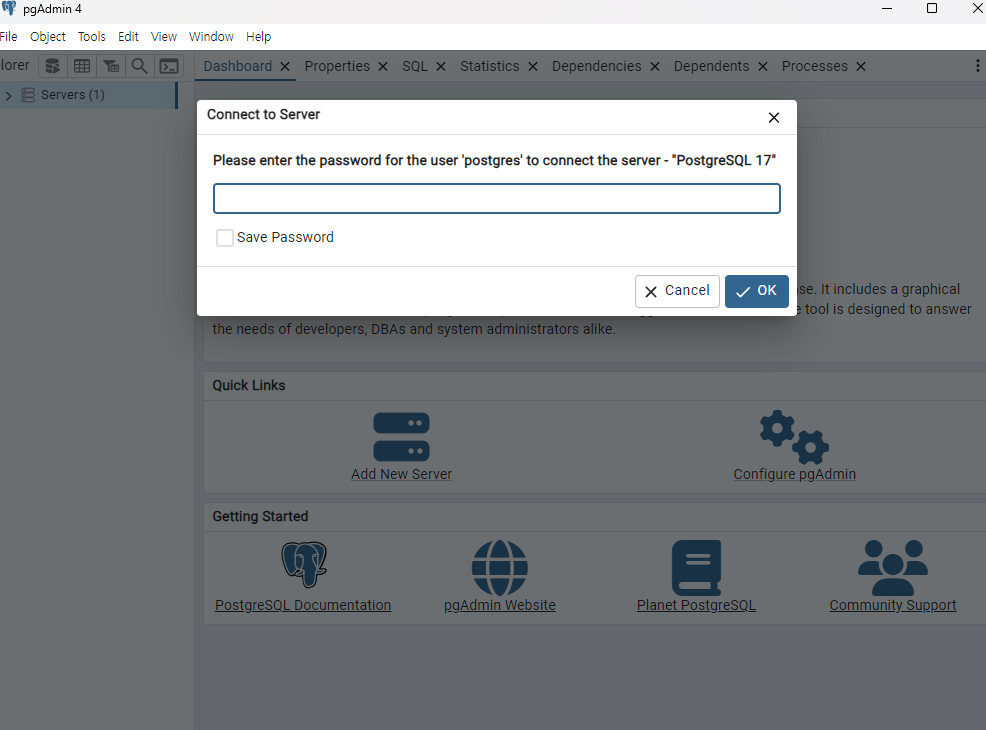
② 비밀번호 입력시 Dashboard 화면 바뀜

③ Tables 위치 확인 : Servers > PostgreSQL > Databases > Postgres > Schemas > public > Tables
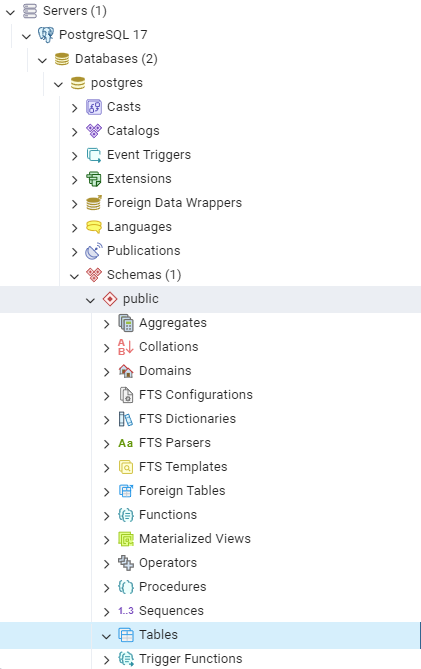
④ 데이터베이스 추가
- Create Database

- 데이터베이스 이름 임의 지정

- 생성된 데이터베이스의 위치 확인
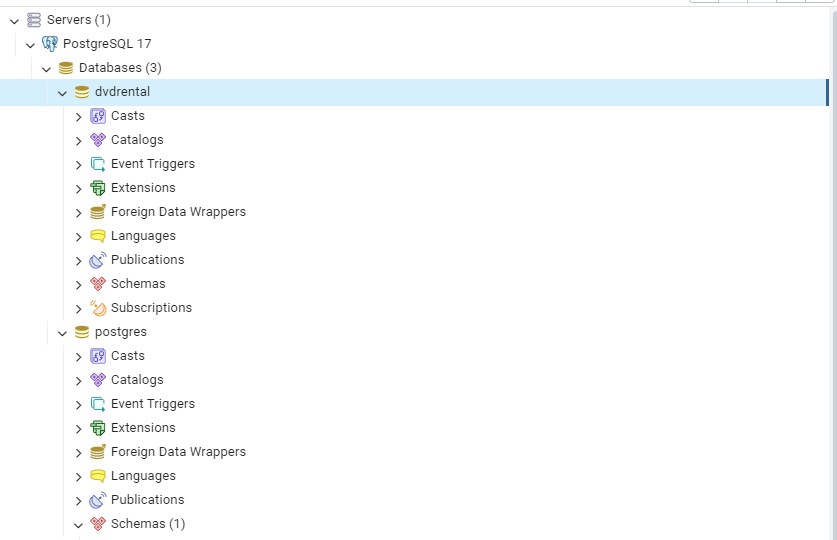
- 데이터베이스 복원(Restore) : 선택한 데이터베이스(dvdrental)을 이전에 백업된 데이터베이스 파일(.tar, .backup, .sql 등)로 복원

⑤ 쿼리문 작성 → 드래그 + F5 로 쿼리문 일부 실행


2. DBeaver
1) DBeaver 란?
- DBeaver : 다양한 데이터베이스를 관리하고 쿼리를 실행할 수 있는 오픈 소스 데이터베이스 관리 도구
- SQL 쿼리를 쉽게 작성하고 실행하며 데이터베이스 구조를 시각적으로 탐색할 수 있음
2) DBeaver - PostgreSQL 연결
① DBeaver 접속 → 새 데이터베이스 연결 아이콘 클릭
② 데이터베이스 선택

③ show all databases 에 체크, PostgreSQL 비밀번호 입력

④ 연결 완료

3) DBeaver 실행
- 새 SQL 편집기 오픈

- 엔티티 관계도 확인; 동그라미 부분이 자식, 그 반대가 부
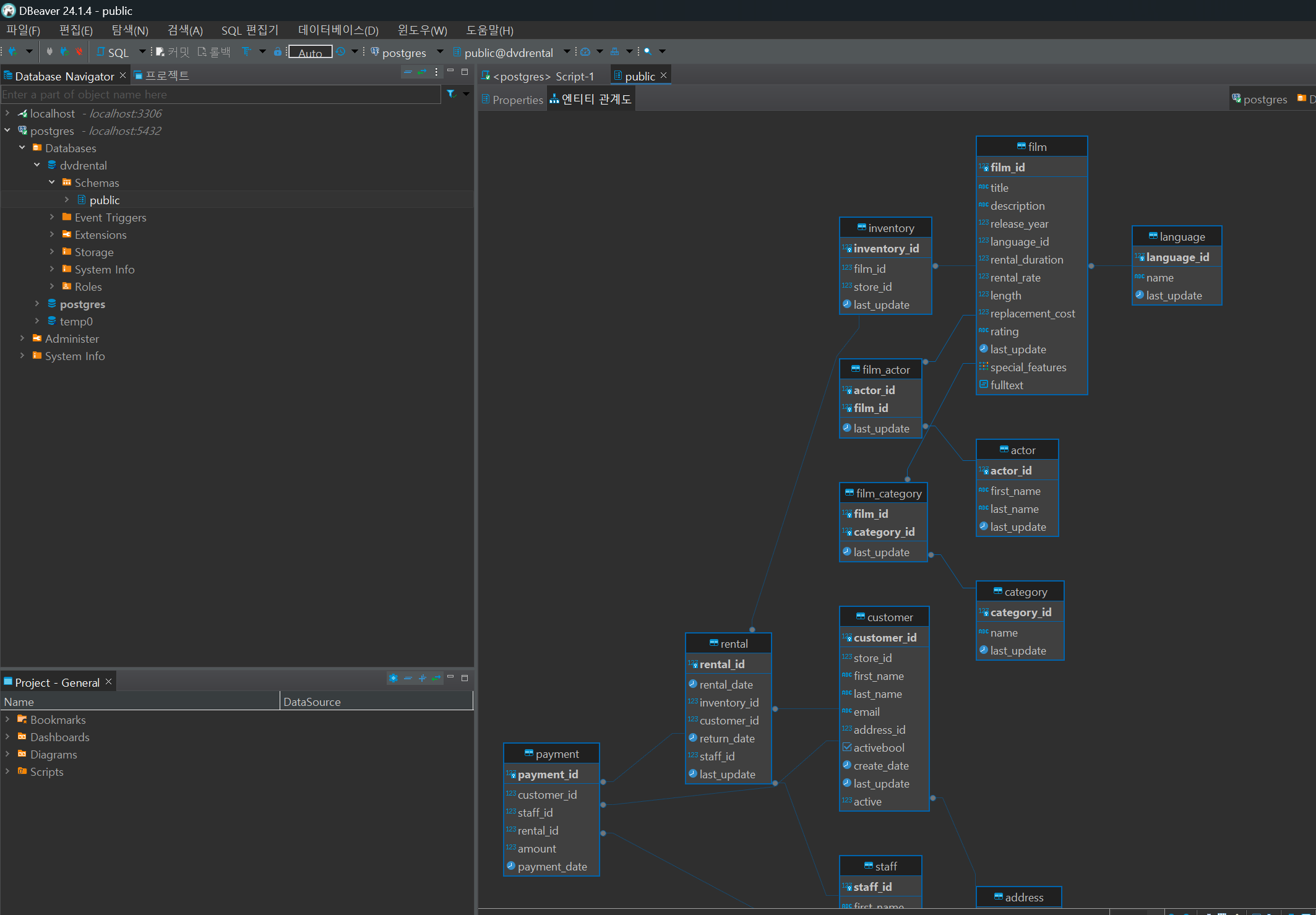
- Active catalog/schema (public@dvdrental) 클릭; active 가능한 DB 리스트 확인


- temp0 선택시 public@temp0 로 바뀜; 쿼리문 작성시 해당 데이터베이스(temp0)에 적용됨
- temp0 데이터베이스에 테이블 생성; 쿼리문 실행 후 새로고침(F5)

- 테이블 제약 조건 확인

- DDL 확인; 실제로 작성한 쿼리문이 나오는게X, 표준 방식으로 생성된 DDL 확인 가능
- 제약조건 생성


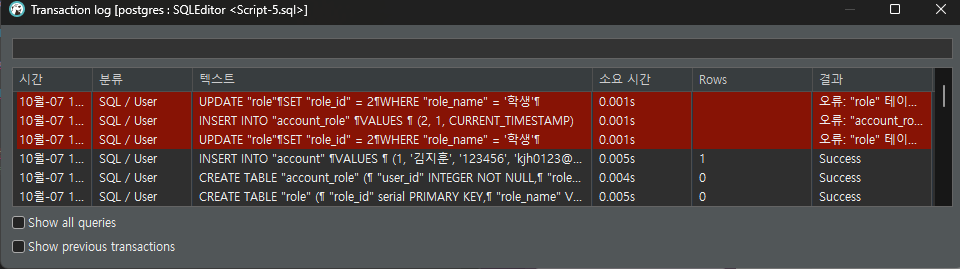
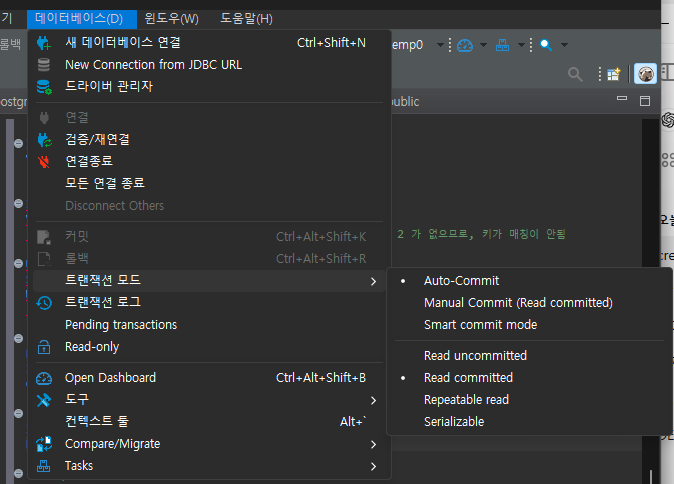
- Auto-commit mode (AUTO) 클릭; Transaction log 확인 가능
- Auto Commit Mode : 모든 쿼리가 자동으로 커밋되며, 즉시 변경 사항이 적용됨. 간편하지만 롤백할 수 X
- Manual Commit Mode : 사용자가 명시적으로 커밋해야 변경 사항이 적용됨. 롤백 가능
- 커밋모드 변경; Manual Commit

3. TCL 명령어
1) SQL 문법의 종류

2) TCL 정의
- TCL (Transaction Control Language) : 데이터베이스에서 트랜잭션의 제어를 담당하는 명령어
- Transaction : 데이터베이스에서 수행되는 일련의 작업을 하나의 단위로 묶어 관리하는 개념. ACID 속성을 준수하여 데이터의 무결성을 보장하며, 여러 작업을 안전하게 수행할 수 있도록 함
- 즉, TCL 명령어는 트랜잭션을 제어할 때 사용하는 SQL 명령어이며, ACID 원칙을 보장하는 수단
- ACID : 트랜잭션을 처리할 때 데이터의 무결성과 안정성을 보장하기 위한 원칙
| ACID 속성 | 설명 | 핵심 요소 | 보장되는 상황 |
| Atomicity (원자성) |
- 트랜잭션 내의 모든 작업이 모두 성공하거나 모두 실패해야 하며, 일부만 완료되는 경우는 허용되지 않음 - 중간에 오류가 발생하면 전체 트랜잭션이 롤백됨 |
트랜잭션의 전체 성공/실패 보장 | 트랜잭션 중 오류가 발생했을 때, 모든 작업을 취소하고 원래 상태로 복원하여 데이터의 무결성을 보장함 |
| Consistency (일관성) |
- 트랜잭션이 완료된 후 데이터베이스가 정의된 규칙에 따라 일관성을 유지해야 함 - 성공적인 트랜잭션 후 데이터는 유효한 상태로 남아야 하며, 데이터 무결성 제약조건이 지켜짐 |
데이터 무결성 유지 | 외래 키, 유니크 키, 체크 제약 조건 등이 트랜잭션이 완료된 후에도 유지되어 일관된 데이터 상태가 보장됨 |
| Isolation (고립성) |
- 동시에 여러 트랜잭션이 실행될 때, 각 트랜잭션이 서로 간섭하지 않고 독립적으로 처리되어야 함 - 다른 트랜잭션이 처리되는 동안 트랜잭션의 중간 상태가 노출되지 않음 |
동시 실행 시 트랜잭션 간 간섭 방지 | 다중 사용자가 동시에 데이터를 읽고 쓸 때, 각 트랜잭션이 서로 독립적으로 실행되어 다른 트랜잭션의 영향을 받지 않도록 보장됨 |
| Durability (지속성) |
- 트랜잭션이 성공적으로 완료된 후에는 그 결과가 영구적으로 데이터베이스에 반영되어 시스템 오류나 장애가 발생하더라도 데이터가 유실되지 않음 | 트랜잭션 결과의 영구 저장 | 시스템이 충돌하거나 장애가 발생해도 성공적으로 완료된 트랜잭션의 데이터는 영구적으로 저장되어, 이후에도 데이터가 안전하게 보존됨 |
3) TCL 명령어 종류
| TCL 명령어 | 설명 | 예시 | 예시 쿼리에 대한 설명 |
| COMMIT | 트랜잭션이 성공적으로 완료되어 변경 사항을 영구적으로 반영 | INSERT INTO "account" (user_id, user_name) VALUES (3, '박수현'); COMMIT; |
INSERT로 삽입된 데이터가 영구적으로 데이터베이스에 반영됨 |
| ROLLBACK | 트랜잭션 내에서 이루어진 모든 변경 사항을 취소하고 이전 상태로 되돌림 | INSERT INTO "account" (user_id, user_name) VALUES (4, '이민지'); ROLLBACK; |
INSERT로 삽입된 데이터가 취소되고, 데이터베이스는 변경 전 상태로 되돌아감 |
| SAVEPOINT | 트랜잭션 내에서 특정 지점을 저장하여, 이후 해당 지점으로 되돌아갈 수 있도록 함 | INSERT INTO "account" (user_id, user_name) VALUES (5, '김지민'); SAVEPOINT "save1"; INSERT INTO "account" (user_id, user_name) VALUES (6, '홍길동'); ROLLBACK TO SAVEPOINT "save1"; COMMIT; |
SAVEPOINT "save1"로 트랜잭션의 중간 지점을 저장한 후, "홍길동" 데이터 삽입만 취소하고, "김지민"의 삽입 내용은 유지됨 |
4) 주의점
- DBeaver에서 TCL 명령어 사용시, 수동 커밋 모드(Manual Commit Mode)로 변경해야 함; 데이터베이스의 무결성을 더 잘 유지할 수 있음
- 즉, 트랜잭션의 진행 상태를 명확히 하고, 원치 않는 데이터 변경을 방지하며, 필요할 경우 롤백할 수 있는 안전성을 제공함
4. ERD
1) 정의
- ERD (Entity-Relationship Diagram) : 개체-관계 다이어그램으로, 데이터베이스의 구조를 시각적으로 표현함
- 데이터베이스 설계를 이해하고, 각 개체(entity)와 그들 간의 관계(relationship)를 명확하게 보여줌

2) 주요 구성 요소
| 구성 요소 | 설명 | 예시 | 표시 |
| Entity (개체) |
- 데이터베이스에서 관리해야 할 객체를 의미 - 개체는 독립적인 존재로, 여러 속성을 가짐 |
학생, 교수, 도서 | 사각형(□) |
| Attributes (속성) |
개체가 가지는 특성(개체를 구체화하는 속성들)을 나타냄 | 이름, 학번, 전공 | 타원형(◯) |
| Relationship (관계) |
개체들 간의 연관성을 나타내며, 두 개체 이상이 서로 연결될 때 사용 | 학생과 수업 사이의 "수강한다" 관계 | 마름모(◇) |
| Primary Key (기본 키) |
- 각 개체를 고유하게 식별할 수 있는 속성 - 동일한 값이 중복될 수 없으며, 개체 내에서 유일함 |
학생의 학번 | 속성 이름 아래에 "PK" 또는 밑줄 |
| Foreign Key (외래 키) |
다른 개체와의 관계를 나타내는 속성. 참조 무결성을 보장하며, 외래 키는 다른 개체의 기본 키를 참조함 | 수업의 교수 아이디, 교수 테이블의 교수 아이디 참조 | 속성 이름 아래에 "FK" |
3) ERD 생성 규칙
① ERD에서 부모-자식 관계
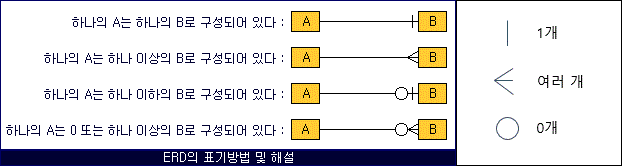
- A는 부모, B는 자식의 관계
- A는 부모 테이블, B는 자식 테이블로서 관계를 나타냄
- '~B로 구성되어 있다' = 'A는 B를 포함하고 있다'
- 부모-자식 관계의 이해
- 부모-자식 관계는 테이블 간의 참조 관계를 뜻하며, A 테이블의 기본키가 B 테이블에서 외래 키로 사용되면, A는 부모 테이블이고, B는 자식 테이블이 됨
- 즉, 부모 테이블의 데이터는 자식 테이블의 데이터와 관계를 가지며, 자식 테이블은 부모 테이블의 데이터에 의존하는 형태
- 실선과 점선의 의미
- 실선: 자식 테이블에서 부모 테이블의 기본키를 외래 키로 사용하며, 그 외래 키가 자식 테이블에서 기본키 역할을 하는 경우에 실선으로 표시됨
- 점선: 자식 테이블에서 부모 테이블의 기본키를 외래 키로 가지고 있지만, 그 외래 키가 자식 테이블에서 기본키 역할을 하지 않는 경우에 점선으로 표시됨
4) ERD 생성 예시
① 학생/수강내역 테이블 간의 관계

- 부모 테이블과 자식 테이블
- 부모 테이블: 학생 테이블
- 자식 테이블: 수강내역 테이블
- 이유: 수강내역 테이블이 학생 테이블의 기본키(학생ID)를 외래 키(FK)로 가지고 있기 때문
- 테이블 간의 관계
- 학생 테이블 쪽의 기호는 '1'을 나타냅. 즉, 하나의 학생이 존재함
- 수강내역 테이블 쪽의 기호는 '0~N'을 나타냄. 즉, 0에서 N개의 수강내역을 가질 수 있음
- 해석:
- 학생의 입장: 하나의 학생은 0~N개의 수강내역을 가질 수 있음
- 수강내역의 입장: 0~N개의 수강내역은 하나의 학생과 연관됨
- 테이블 간의 관계선
- 실선: 수강내역 테이블에서 학생 테이블의 기본키(학생ID)를 자신의 기본키로도 사용하고 있으므로, 두 테이블 사이의 관계는 실선으로 표시됨
② 부서/사원 테이블 간의 관
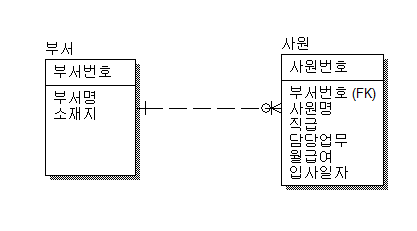
- 부모 테이블과 자식 테이블
- 부모 테이블: 부서 테이블
- 자식 테이블: 사원 테이블
- 이유: 사원 테이블이 부서 테이블의 기본키(부서번호)를 외래 키(FK)로 가지고 있기 때문
- 테이블 간의 관계
- 부서 테이블 쪽의 기호는 '1'을 나타냄. 즉, 하나의 부서가 존재
- 사원 테이블 쪽의 기호는 '0~N'을 나타냄. 즉, 0에서 N명의 사원이 한 부서에 속할 수 있음
- 해석:
- 부서의 입장: 하나의 부서는 0~N명의 사원을 가질 수 있슴
- 사원의 입장: 0~N명의 사원은 하나의 부서에 속함
- 테이블 간의 관계선
- 점선: 부서 테이블의 기본키(부서번호)가 사원 테이블에서 외래 키로 사용되지만, 사원 테이블에서는 기본키로 사용되지 않으므로 점선으로 표시됨
- FK 표시: 사원 테이블에서 부서번호가 외래 키(FK)로 사용됨
5. 테이블 생성
1) 테이블 생성시 유의할 점
- 테이블 이름
- 다른 테이블과 이름이 중복되지 않아야 함
- 문자로 시작해야 하며, 경우에 따라 길이 제한이 있을 수 있음
- 사용 가능한 문자: 영어 대/소문자(A-Z, a-z), 숫자(0-9), 밑줄(_), 달러($), 해시(#) 기호
- 컬럼 이름
- 한 테이블 내에서는 컬럼명이 중복될 수 없음
- 컬럼명 역시 문자로 시작해야 하며, 경우에 따라 길이 제한이 있을 수 있음
- 사용 가능한 문자: 테이블 이름과 동일하게 영어 대/소문자(A-Z, a-z), 숫자(0-9), 밑줄(_), 달러($), 해시(#) 기호
- 테이블 및 컬럼 정의 문법
- 테이블 이름을 지정하고, 각 컬럼을 괄호로 묶어 지정
- 각 컬럼은 콤마(,)로 구분
- 테이블 생성문의 끝은 세미콜론(;)으로 마무리
- 데이터 유형 지정
- 각 컬럼 뒤에 반드시 데이터 유형이 지정되어야 함 (예: VARCHAR, INT, DATE 등)
- 예시
CREATE TABLE employees (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
hire_date DATE
);
2) 제약 조건 : 데이터 무결성을 위해, 테이블 생성 시 제약 조건을 걸 수 있음
| 제약 조건 명 | 설명 |
| NOT NULL | 컬럼의 값으로 NULL이 허용되지 않음 |
| UNIQUE | 컬럼의 값이 테이블 내에서 유일해야 함 |
| PRIMARY KEY | 컬럼의 값이 테이블 내에서 유일해야 함 + 컬럼의 값으로 NULL이 허용되지 않음 |
| CHECK | 지정된 조건에 맞는 값 만을 허용 |
| REFERENCES | 컬럼의 값이 참조하는 테이블의 특정 컬럼에 값으로 존재해야 함 |
6. 데이터 소스 vs 데이터베이스 vs 데이터 스키마 vs 테이블
| 항목 | 데이터 소스 | 데이터베이스 | 데이터 스키마 | 테이블 |
| 정의 | 데이터를 제공하는 원천(예: 파일, API, DBMS 등)로, 데이터가 어디에서 오는지 나타냄 | - 데이터를 저장, 관리하는 시스템 또는 구조 - 데이터의 집합을 관리하는 공간 |
- 데이터베이스 내에서 테이블과 관련된 구조적 설계를 정의한 것 - 테이블, 뷰, 관계 등을 정의한 논리적 그룹 |
- 실제 데이터를 저장하는 행과 열로 구성된 구조 - 특정 주제나 엔터티에 대한 데이터를 저장하는 단위 |
| 역할 | - 데이터를 수집하거나 읽어오는 곳 - 다양한 소스가 존재할 수 있으며, 각 소스는 데이터베이스로 데이터를 전달함 |
데이터베이스는 데이터를 저장, 검색, 관리할 수 있는 중앙 저장소 역할 | 데이터베이스의 논리적 구성을 위한 설계 도구로, 데이터 구조와 관계를 정의하는 역할 | 데이터를 구체적으로 저장하는 곳으로, 스키마 내에서 가장 작은 단위의 데이터 저장소 |
| 구성 요소 | API, 파일 시스템, 클라우드 스토리지, 센서, DBMS 등의 데이터 원천 | 여러 스키마, 테이블, 뷰, 인덱스, 트리거, 저장 프로시저 등으로 구성됨 | 여러 테이블, 뷰, 인덱스, 권한, 트리거 등이 포함될 수 있음 | - 여러 행과 열로 구성된 데이터 - 각 컬럼은 속성을 나타내며, 각 행은 개별 데이터를 나타냄 |
| 사용 예 | 클라우드 API로부터 데이터를 가져와서 분석에 사용하거나, CSV 파일을 로드하여 데이터베이스에 입력 | 회사의 판매 데이터, 직원 정보, 제품 정보 등을 저장하고 관리하기 위한 데이터베이스 시스템 | sales, hr 같은 논리적 그룹으로 회사 내의 서로 다른 영역을 관리하는 스키마 | employees, products, orders와 같은 테이블에 구체적인 데이터가 저장됨 |
| 의존 관계 | 데이터 소스는 데이터베이스로 데이터를 전달하며, 데이터베이스의 기초를 제공함 | 데이터베이스는 여러 소스에서 데이터를 받아 저장하며, 스키마를 통해 데이터 구조를 정의함 | 스키마는 데이터베이스의 논리적 구조를 정의하며, 테이블을 포함하여 데이터베이스 내 데이터를 체계화함 | 테이블은 스키마 내에 속하며, 스키마에서 정의된 구조를 따름 |
7. 정규화
1) 정의
- 정규화(Normalization) : 데이터베이스 설계에서 중복된 데이터를 최소화하고 데이터 무결성을 유지하기 위한 과정
2) 정규화 단계
- 정규화는 여러 단계로 나뉘며, 각 단계에서 데이터를 더 효율적으로 저장하고 관리하기 위해 테이블을 분해함
- 제1 정규화: 컬럼이 원자값을 갖도록 분해
- 제2 정규화: 완전 함수 종속을 만족하도록 테이블 분해
- 제3 정규화: 이행적 종속을 제거
- BCNF ( Boyce-Codd Normal Form, 보이스-코드 정규형): 모든 결정자가 후보키가 되도록 분해
📘 쿼리 실습
1. AWS Athena 쿼리문 작성
1) GROUP BY의 여러가지 방법
| 그룹화 방법 | 설명 | 예시 쿼리문 | 쿼리문 설명 |
| GROUP BY | - 지정한 열들의 조합에 대해 그룹화 - 각 조합에 대해 하나의 결과 반환 | GROUP BY "ymd", "sex"; | 날짜(ymd)와 성별(sex)로 그룹화 |
| GROUP BY GROUPING SETS |
- 여러 열들 각각에 대해 개별적으로 그룹화된 결과 반환 - 특정 열 조합만 선택하여 그룹화 가능 |
GROUP BY GROUPING SETS ("ymd", "sex"); | - 날짜(ymd)로 그룹화 - 성별(sex)로 그룹화 |
| GROUP BY ROLLUP |
- 계층적 그룹화 - 지정된 열의 순서대로 점진적으로 더 넓은 범위로 그룹화하며 마지막엔 전체 데이터를 그룹화 |
GROUP BY ROLLUP ("ymd", "sex"); | - 날짜(ymd)와 성별(sex)로 그룹화 - 날짜(ymd)로 그룹화 - 전체 데이터에 대한 집계; 성별과 날짜를 모두 무시하고 데이터 전체 총합을 반환 |
| GROUP BY CUBE |
- 지정된 열들의 가능한 모든 조합에 대해 그룹화하여 각 조합에 대한 결과 반환 | GROUP BY CUBE ("ymd", "sex"); | - 날짜(ymd)와 성별(sex)로 그룹화 - 날짜(ymd)로 그룹화 - 성별(sex)로 그룹화 - 전체 데이터에 대한 집계; 성별과 날짜를 모두 무시하고 데이터 전체 총합을 반환 |
① GROUP BY
SELECT "proc_ymd", "mbr_sex_cd_nm", COUNT("userid") AS "user_cnt" FROM "learning_analytics"."e_milkt_study" WHERE 1=1 AND "proc_ym" = '202409' AND "proc_ymd" IS NOT NULL AND "mbr_sex_cd_nm" IS NOT NULL GROUP BY "proc_ymd", "mbr_sex_cd_nm" -- 지정된 두 열에 대해 조합별로 그룹화됨 ORDER BY "proc_ymd", "mbr_sex_cd_nm";
② GROUP BY GROUPING SETSSELECT "proc_ymd", "mbr_sex_cd_nm", COUNT("userid") AS "user_cnt" FROM "learning_analytics"."e_milkt_study" WHERE 1=1 AND "proc_ym" = '202409' AND "proc_ymd" IS NOT NULL AND "mbr_sex_cd_nm" IS NOT NULL GROUP BY GROUPING SETS ("proc_ymd", "mbr_sex_cd_nm") -- 각 열에 대해 개별적으로 그룹화된 결과 반환 ORDER BY "proc_ymd", "mbr_sex_cd_nm";
③ GROUP BY ROLLUPSELECT "proc_ymd", "mbr_sex_cd_nm", COUNT("userid") AS "user_cnt" FROM "learning_analytics"."e_milkt_study" WHERE 1=1 AND "proc_ym" = '202409' AND "proc_ymd" IS NOT NULL AND "mbr_sex_cd_nm" IS NOT NULL GROUP BY ROLLUP ("proc_ymd", "mbr_sex_cd_nm") -- 계층적으로 그룹화된 결과 반환 ORDER BY "proc_ymd", "mbr_sex_cd_nm";
④ GROUP BY CUBESELECT "proc_ymd", "mbr_sex_cd_nm", COUNT("userid") AS "user_cnt" FROM "learning_analytics"."e_milkt_study" WHERE 1=1 AND "proc_ym" = '202409' AND "proc_ymd" IS NOT NULL AND "mbr_sex_cd_nm" IS NOT NULL GROUP BY CUBE ("proc_ymd", "mbr_sex_cd_nm") -- 모든 가능한 조합에 대해 그룹화된 결과 반환 ORDER BY "proc_ymd", "mbr_sex_cd_nm";
2) NULL 값이 있는 컬럼에서의 정렬
NULL 값의 위치 확인
-- 테이블 형태 확인 SELECT "proc_ymd", "userid", "cjt050_timestamp" FROM "learning_analytics"."e_media" LIMIT 5; -- NULL 값의 위치 확인 SELECT "proc_ymd", "userid", "cjt050_timestamp" FROM "learning_analytics"."e_media" WHERE 1=1 AND "proc_ymd" = '20210929' AND "userid" = '0001809c-1725-4ccd-86b0-d02ed0937a83' ORDER BY "cjt050_timestamp" DESC NULLS LAST -- NULL을 맨 뒤에 오게 정렬 ;
3) 윈도우 함수
SELECT "proc_ymd", "userid", "cjt050_timestamp", RANK() OVER( PARTITION BY "proc_ymd", "userid" ORDER BY "cjt050_timestamp" ASC NULLS FIRST -- 여기에 NULLS FIRST 입력시; NULL이 앞에 정렬됨 & 젤 높은 순위 부여 ) AS "rank" FROM "learning_analytics"."e_media" WHERE 1=1 AND "proc_ymd" = '20210929' AND "userid" = '0001809c-1725-4ccd-86b0-d02ed0937a83' -- ORDER BY "cjt050_timestamp" ASC NULLS FIRST -- 여기에 NULLS FIRST 입력시; NULL이 앞에 정렬은 되지만 젤 낮은 순위 부여(기본값) -- ORDER BY "rank" ASC -- 적나 안적나 결과 같음 ;
2. DBeaver 쿼리문 작성
1) 테이블 생성, 구조 변경 (DDL; 데이터 정의 언어)
① 테이블 생성
CREATE TABLE "imsi0" ( "col0" VARCHAR, "col1" INT, "col2" TIMESTAMP );
② 테이블 구조 변경-- 컬럼 추가 ALTER TABLE "imsi0" ADD COLUMN "col3" VARCHAR; -- 컬럼 삭제 ALTER TABLE "imsi0" DROP COLUMN "col3"; -- 컬럼명 변경 ALTER TABLE "imsi0" RENAME COLUMN "col0" TO "text"; -- 테이블명 변경 ALTER TABLE "imsi0" RENAME TO "imsi1"; -- 컬럼 데이터 타입 변경 ALTER TABLE "imsi1" ALTER COLUMN "col1" TYPE FLOAT; -- 테이블 삭제 DROP TABLE "imsi1";
2) 테이블 조작, 데이터 삽입 (DML; 데이터 조작 언어)
① 테이블 생성 및 컬럼 추가
-- 테이블 생성 CREATE TABLE "today_study" ( "today" CHAR(8), "summary" VARCHAR, "note" VARCHAR ); -- 컬럼 추가 ALTER TABLE "today_study" ADD COLUMN "idx" INT;
② 데이터 삽입
-- 단일 행 삽입 INSERT INTO "today_study" ( "today", "summary", "note", "idx" ) VALUES ( '20240930', '오리엔테이션', ' ', 1 ); -- 다중 행 삽입 INSERT INTO "today_study" ( "today", "summary", "note", "idx" ) VALUES ('20240930', '관련직무', ' ', 2), ('20240930', '환경구성', ' ', 3), ('20240930', '데이터의 위치', ' ', 2), ('20240930', '데이터의 종류', ' ', 3);
3) 백업 테이블 생성, 데이터 백업 (DDL 및 DML)
① 백업 테이블 생성 (값 없이 구조만 복사)
* 여기서 AS는 별칭을 지정하는 것이 아니라, SELECT문을 사용하여 새로운 테이블을 생성할 때 사용하는 구문. "today_study" 테이블의 구조만 복사해서 빈 테이블을 만드는 데에 쓰인 것
CREATE TABLE "today_study_backup" AS SELECT * FROM "today_study" WHERE 0=1; -- 계속 FALSE; 값은 비어있지만, 테이블 구조(컬럼)는 생성됨
② 백업 테이블 생성 (구조 + 값 복사)
CREATE TABLE "today_study_backup_2" AS SELECT * FROM "today_study_backup" WHERE 1=1;
③ 백업 테이블에 값(데이터) 삽입
INSERT INTO "today_study_backup" SELECT * FROM "today_study";
4) 데이터 업데이트, 삭제 (DML)
① 데이터 업데이트
-- 특정 값 변경 UPDATE "today_study" SET "idx" = 4 -- 2. 이렇게 바꿔줌 (기존의 행 삭제 후, 테이블 맨 아래에 NEW 행 추가) WHERE "summary" = '데이터의 위치'; -- 1. 이 조건을 만족하는 행을 찾아서 -- 다른 값 업데이트 UPDATE "today_study" SET "idx" = 5 WHERE "summary" = '데이터의 종류'; -- 특정 값 NULL로 설정 UPDATE "today_study" SET "note" = NULL WHERE "note" = ' ';
② 데이터 삭제
-- 조건에 맞는 일부 데이터 삭제 -- 전체 데이터 삭제 -- DELETE 사용; 값만 삭제(테이블 유지), 로그 남김 DELETE FROM "today_study"; -- TRUNCATE 사용; 값만 삭제(테이블 유지), 로그 남기지 않음 TRUNCATE TABLE "today_study_backup"; -- DROP 사용; 테이블 완전히 삭제 DROP TABLE "today_study";
5) 테이블 생성, 제약조건 설정 (DDL)
① 테이블 구조 확인
SELECT * FROM "actor" LIMIT 5; SELECT * FROM "film_actor" LIMIT 5; SELECT * FROM "film" LIMIT 5;
② 테이블 생성
CREATE TABLE "account" ( "user_id" SERIAL PRIMARY KEY, "user_name" VARCHAR(50) UNIQUE NOT NULL, "password" VARCHAR(50) NOT NULL, "email" VARCHAR(500) UNIQUE NOT NULL, "created_on" TIMESTAMP NOT NULL, "last_login" TIMESTAMP );
③ 새로운 테이블 생성 + 외래 키 설정
-- account 테이블 생성 CREATE TABLE "account" ( "user_id" SERIAL PRIMARY KEY, "user_name" VARCHAR(50) UNIQUE NOT NULL, "password" VARCHAR(50) NOT NULL, "email" VARCHAR(500) UNIQUE NOT NULL, "created_on" TIMESTAMP NOT NULL, "last_login" TIMESTAMP ); -- role 테이블 생성 CREATE TABLE "role" ( "role_id" SERIAL PRIMARY KEY, "role_name" VARCHAR(255) UNIQUE NOT NULL ); -- account_role 테이블 생성 + 외래 키 설정 CREATE TABLE "account_role" ( "user_id" INTEGER NOT NULL, "role_id" INTEGER NOT NULL, "grant_date" TIMESTAMP WITHOUT TIME ZONE, PRIMARY KEY ("user_id", "role_id"), CONSTRAINT "account_role_role_id_fkey" FOREIGN KEY ("role_id") REFERENCES "role" ("role_id") MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT "account_role_user_id_fkey" FOREIGN KEY ("user_id") REFERENCES "account" ("user_id") MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION );
6) 데이터 조작, 제약조건 처리 (DML)
① 값 삽입
-- 값 삽입 INSERT INTO "account" VALUES (1, '김지훈', '123456', 'kjh0123@chunjae.co.kr', CURRENT_TIMESTAMP, NULL); -- 중복 및 NULL 제약조건 위반 INSERT INTO "account" VALUES (2, '김지훈', '456', 'kjh01234@chunjae.co.kr', CURRENT_TIMESTAMP, NULL); -- ERROR: UNIQUE 제약 위반(중복 데이터 입력 불가) INSERT INTO "account" VALUES (2, NULL, '456', 'kjh01234@chunjae.co.kr', CURRENT_TIMESTAMP, NULL); -- ERROR: NOT NULL 제약 위반(NULL 데이터 입력 불가)
② 제약조건 추가/제거
-- UNIQUE 제약조건 추가/제거 -- UNIQUE: 중복된 값X ALTER TABLE "account" ADD CONSTRAINT "unique_password" UNIQUE ("password"); ALTER TABLE "account" DROP CONSTRAINT "unique_password"; -- NOT NULL 제약조건 추가/제거 -- NOT NULL: NULL 값 허용X ALTER TABLE "account" ALTER COLUMN "password" SET NOT NULL; ALTER TABLE "account" ALTER COLUMN "password" DROP NOT NULL; -- PRIMARY KEY 제약조건 추가/제거 -- PRIMARY KEY: 중복된 값X, NULL 값 허용X ALTER TABLE "account" ADD CONSTRAINT "account_pkey" PRIMARY KEY ("user_id"); ALTER TABLE "account" DROP CONSTRAINT "account_pkey"; -- CHECK 제약조건 추가/제거 -- CHECK: 데이터의 유효성을 검증(테이블에 데이터가 입력될 때 지정된 조건을 만족하는지 확인) ALTER TABLE "account" ADD CONSTRAINT "check_password" CHECK("password" ~ '^[0-9]+$'); ALTER TABLE "account" DROP CONSTRAINT "check_password";
7) 트랜젝션 제어 (TCL; 트랜젝션 제어 언어)
* DBeaver에서 TCL 명령어 사용시, 수동 커밋 모드(Manual Commit Mode)로 변경해야 함; 데이터베이스의 무결성을 더 잘 유지할 수 있음
① COMMIT, ROLLBACK
-- INSERT 후 COMMIT INSERT INTO "role1" VALUES (2, '교사'); COMMIT; -- INSERT 후 ROLLBACK INSERT INTO "role1" VALUES (3, '친구'); ROLLBACK;
② SAVEPOINT 사용
INSERT INTO "role1" VALUES (4, '부모'); SAVEPOINT "mysave"; INSERT INTO "role1" VALUES (5, 'asdf'); ROLLBACK TO SAVEPOINT "mysave"; INSERT INTO "role1" VALUES (5, '친인척'); COMMIT;
8) 데이터 업데이트, 삭제 (DML)
① 값 업데이트
UPDATE "account" SET "password" = '123456' WHERE "user_id" = 2;
② 외래 키 업데이트
INSERT INTO "account_role" VALUES (1, 1, CURRENT_TIMESTAMP); INSERT INTO "account_role" VALUES (2, 1, CURRENT_TIMESTAMP); -- ERROR: 외래 키 매칭 실패 UPDATE "role" SET "role_id" = 2 WHERE "role_name" = '학생'; -- ERROR: 외래 키 매칭 실패
9) 테이블 제거, 재생성 (DDL)
① 테이블 제거
DROP TABLE "account";
② 테이블 재생성
-- account 테이블 재생성 CREATE TABLE "account" ( "user_id" SERIAL PRIMARY KEY, "user_name" VARCHAR(50) UNIQUE NOT NULL, "password" VARCHAR(50) NOT NULL, "email" VARCHAR(500) UNIQUE NOT NULL, "created_on" TIMESTAMP NOT NULL, "last_login" TIMESTAMP ); -- role, accoun_role 테이블 재생성 CREATE TABLE "role" ( "role_id" SERIAL PRIMARY KEY, "role_name" VARCHAR(255) UNIQUE NOT NULL ); CREATE TABLE "account_role" ( "user_id" INTEGER NOT NULL, "role_id" INTEGER NOT NULL, "grant_date" TIMESTAMP WITHOUT TIME ZONE, PRIMARY KEY ("user_id", "role_id"), CONSTRAINT "account_role_role_id_fkey" FOREIGN KEY ("role_id") --외래 키 제약조건의 이름("account_role_role_id_fkey") 지정 REFERENCES "role" ("role_id") MATCH SIMPLE -- 외래 키가 참조하는 테이블("role")과 열("role_id")을 지정 -- MATCH SIMPLE : PostgreSQL에서 외래 키 일치 조건을 지정. MATCH SIMPLE은 가장 기본적인 외래 키 일치 방식으로, 개별 값에 대해 일치를 검사함. 즉, "role_id" 열에 대해 각 값이 개별적으로 참조 테이블의 값과 일치해야 함 ON UPDATE NO ACTION ON DELETE NO ACTION, -- 참조되는 테이블의 role_id 값이 변경(UPDATE)될 때, 이 외래 키 제약조건에 의한 별다른 조치가 취해지지 않는다(account 테이블에서 아무런 행동을 취하지 않음)는 의미. 변경된 값이 account 테이블에 이미 존재하는 경우, 무결성 오류가 발생할 수 있음 CONSTRAINT "account_role_user_id_fkey" FOREIGN KEY ("user_id") REFERENCES "account" ("user_id") MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION );
📙 내일 일정
- MongoDB 실습

'TIL _Today I Learned > 2024.10' 카테고리의 다른 글
| [DAY 59] 자연어 처리 (NLP) (2) | 2024.10.14 |
|---|---|
| [DAY 58] 자연어 처리 (NLP) (1) | 2024.10.11 |
| [DAY 57] SQL 실습 (0) | 2024.10.10 |
| [DAY 56] 비관계형 데이터베이스 (0) | 2024.10.08 |
| [DAY 54] SQL의 응용 (2) | 2024.10.02 |



