[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.10.02
📕 학습 목록
- 데이터 타입
- SQL 함수
- 윈도우 함수
- JOIN
- UNION
- WITH
* Amazon Athena 의 데이터 형식 : https://docs.aws.amazon.com/ko_kr/athena/latest/ug/data-types.html
📗 기억할 내용
1. 데이터 타입
1) 문자형 데이터 (String Types)
| 데이터 타입 | 설명 | 예시 |
| VARCHAR (Variable Character) |
가변 길이의 문자열을 저장하는 데이터 타입 | 'Hello', 'JohnDoe123' |
| CHAR/CHARACTER | 고정 길이의 문자열을 저장하는 데이터 타입. 지정된 길이보다 짧은 문자열은 나머지를 공백으로 채움 | CHAR(10) → 'Hello ' (10자로 고정) |
| STRING | 문자열 데이터를 저장하는 데이터 타입 (주로 VARCHAR와 비슷한 역할) | 'This is a string' |
| TEXT | 큰 텍스트 블록을 저장하는 데이터 타입. 길이에 제한이 거의 없음 | 긴 설명이나 블로그 글 저장 등 |
| BINARY | 이진 데이터를 저장하는 데이터 타입. 바이트 시퀀스로 데이터를 처리 | 이미지나 파일 데이터 저장 |
| VARBINARY (Variable Binary) |
가변 길이의 이진 데이터를 저장하는 데이터 타입 | VARBINARY(50)은 50 바이트 크기의 이진 데이터 |
2) 수치형 데이터 (Numeric Types)
* 부동소수점 (Floating-point)
- 개념: 소수점의 위치가 고정되지 않고 자유롭게 이동할 수 있는 방식
- 표현 방식: 부동소수점은 과학적 표기법을 사용하여 소수를 표현함. 예를 들어, 0.00001234567이라는 숫자는 부동소수점 방식으로 1.234567 × 10^-5와 같은 방식으로 표현될 수 있음. 여기서 소수점 위치가 숫자의 크기에 따라 이동할 수 있는 것이 특징임
- 장점: 매우 큰 숫자나 매우 작은 숫자를 유동적으로 표현할 수 있어 다양한 값의 범위를 다룰 수 있음. 예를 들어, 3.14159, 1234567890.0, 0.000000123 등
- 단점: 계산 과정에서 반올림 오류가 발생할 수 있으며, 정확도가 중요한 애플리케이션에서는 오차가 문제가 될 수 있음. 예를 들어, 0.1과 0.2를 더하면 0.3이 아닌 0.30000000000000004로 표현되는 경우가 있을 수 있음
* 고정소수점 (Fixed-point)
- 개념: 소수점의 위치가 고정된 방식. 숫자의 정수부와 소수부의 자릿수를 미리 정해놓고 그에 따라 숫자를 표현함
- 표현 방식: 예를 들어, 고정소수점으로 소수점 이하 2자리를 지정한 경우, 12345.67처럼 항상 소수점 이하 2자리까지만 표현할 수 있음. 이때 12345.678이라는 숫자는 고정소수점에서 12345.67로 반올림됨
- 장점: 계산이 부동소수점보다 빠르고 간단하며, 반올림 오류가 적어 정확도가 더 높을 수 있음. 예를 들어, 금융 애플리케이션에서 금액을 정확하게 계산할 때 고정소수점 방식이 유리함. 100.12 + 200.34 = 300.46과 같이 정확하게 표현됨
- 단점: 표현할 수 있는 숫자의 범위가 제한되어 있으며, 매우 큰 수나 매우 작은 수를 표현하기 어려움. 예를 들어, 고정소수점에서 99999.99를 넘는 숫자는 표현할 수 없거나 오버플로우가 발생할 수 있음
| 데이터 타입 | 설명 | 예시 |
| NUMBER/NUMERIC/ DECIMAL |
정밀한 숫자 데이터를 저장할 때 사용되는 데이터 타입 | DECIMAL(10, 2) → 12345678.90 (총 10자리 숫자를 나타내며, 그중에서 소수점 이하 2자리를 부여) |
| INT/INTEGER | 정수형 데이터를 저장하는 데이터 타입 | 10, -5 |
| BIGINT | 매우 큰 정수 데이터를 저장하는 데이터 타입 | 9223372036854775807 (64비트 정수) |
| SMALLINT | 작은 범위의 정수 데이터를 저장하는 데이터 타입 | 32767 (16비트 정수) |
| TINYINT | 아주 작은 정수 데이터를 저장하는 데이터 타입 | 255 (8비트 정수) |
| BYTEINT | 1바이트 크기의 정수 데이터를 저장하는 데이터 타입 | 127 (7비트 정수) |
| FLOAT/FLOAT4/FLOAT8 | 부동 소수점 숫자를 저장하는 데이터 타입 | 3.14, -0.0001 (FLOAT4: 4바이트, FLOAT8: 8바이트) |
| DOUBLE/ DOUBLE PRECISION |
더 정밀한 부동 소수점 데이터를 저장하는 데이터 타입 | 12345678.12345678 |
| REAL | 부동 소수점 숫자를 표현하는 데이터 타입. DOUBLE과 유사하지만 정밀도가 약간 낮음 | 부동 소수점 값 표현. |
3) 날짜 및 시간 데이터 (Date/Time Types)
| 데이터 타입 | 설명 | 예시 |
| DATE | 날짜 데이터를 저장하는 데이터 타입 (연-월-일) | 2024-03-01 |
| DATETIME | 날짜와 시간을 함께 저장하는 데이터 타입 | 2024-03-01 12:34:56 |
| TIME | 시간 데이터를 저장하는 데이터 타입 (시-분-초) | 12:34:56 |
| TIMESTAMP | 날짜와 시간을 조합한 데이터 타입. 타임존 정보 포함 가능 | 2024-03-01 12:34:56 UTC |
4) 논리형 데이터 (Boolean Type)
- BOOLEAN : 참/거짓(TRUE/FALSE) 값을 저장하는 데이터 타입
2. SQL 함수
1) 문자열 데이터와 함께 사용되는 함수
| 함수명 | 설명 | 예시 |
| POSITION | 문자열 내에서 특정 문자의 위치를 반환하는 함수 | POSITION('a' IN 'abc') → 1 |
| SUBSTRING | - 문자열의 일부를 추출하는 함수 - SUBSTRING(문자열or컬럼, 자르기 시작할 위치, 잘라낼 문자열 길이) |
SUBSTRING('abcdef', 2, 3) → 'bcd' |
| RIGHT | 문자열의 오른쪽에서 지정된 개수만큼 문자를 반환하는 함수 | RIGHT('abcdef', 3) → 'def' |
| LEFT | 문자열의 왼쪽에서 지정된 개수만큼 문자를 반환하는 함수 | LEFT('abcdef', 3) → 'abc' |
| RPAD | 오른쪽에 지정된 문자를 채워 길이를 맞춤 | RPAD('abc', 5, '*') → 'abc**' |
| LPAD | 왼쪽에 지정된 문자를 채워 길이를 맞춤 | LPAD('abc', 5, '*') → '**abc' |
| UPPER | 문자열을 대문자로 변환하는 함수 | UPPER('abc') → 'ABC' |
| LOWER | 문자열을 소문자로 변환하는 함수 | LOWER('ABC') → 'abc' |
| LENGTH | 문자열의 길이를 반환하는 함수 | LENGTH('abcdef') → 6 |
| CONCAT | - 두 개 이상의 문자열을 하나로 연결하는 함수 - 숫자도 문자열이기만 하면 합칠 수 있음 |
CONCAT('abc', 'def') → 'abcdef' |
| REPLACE | 문자열의 일부를 다른 문자열로 대체하는 함수 | REPLACE('abcabc', 'a', 'z') → 'zbczbc' |
2) 수치형 데이터와 함께 사용되는 함수
| 함수명 | 설명 | 예시 |
| ABS | 숫자의 절대값을 반환하는 함수 | ABS(-10) → 10 |
| CEILING | 소수점 이하를 올림하여 가장 큰 정수를 반환하는 함수 | CEILING(4.3) → 5 |
| FLOOR | 소수점 이하를 내림하여 가장 작은 정수를 반환하는 함수 | FLOOR(4.7) → 4 |
| ROUND | 반올림하여 지정된 소수점 자리까지 나타내는 함수 | ROUND(4.567, 2) → 4.57 |
| TRUNCATE | 소수점을 잘라내어 지정된 자리까지 나타내는 함수 | TRUNCATE(4.567, 2) → 4.56 |
| POWER | 첫 번째 숫자를 두 번째 숫자로 거듭제곱하는 함수 | POWER(2, 3) → 8 |
| MOD | 첫 번째 숫자를 두 번째 숫자로 나눈 나머지를 반환하는 함수 | MOD(10, 3) → 1 |
3) 날짜형 데이터와 함께 사용되는 함수
* 날짜 형식 코드
1. %Y-%m-%d (예: 2024-10-02)
- %Y: 4자리 연도 (예: 2024)- %m: 2자리 월 (예: 01 ~ 12)
- %d: 2자리 일 (예: 01 ~ 31)
* 시간 형식 코드
1. %H:%i:%s (예: 14:15:30)
- %H: 2자리 시 (24시간제) (예: 00 ~ 23)
- %i: 2자리 분 (예: 00 ~ 59)
- %s: 2자리 초 (예: 00 ~ 59)
2. %r
- %r: 시간 (12시간제) (예: 02:15:30 PM)
3. %T
- %T: 시간 (24시간제) (예: 14:15:30)
| 함수명 | 설명 | 예시 |
| NOW | 현재 날짜와 시간을 반환하는 함수 | NOW() → 2024-03-01 12:34:56 |
| YEAR | 주어진 날짜에서 연도를 추출하는 함수 | YEAR('2024-03-01') → 2024 |
| QUARTER | 해당 연도 기준으로 몇 번째 분기인지를 반환 (1~4분기) | QUARTER('2024-03-01') → 1 |
| MONTH | 주어진 날짜에서 월을 추출하는 함수 | MONTH('2024-03-01') → 3 |
| WEEK | 해당 연도 기준으로 몇 번째 주인지를 반환 | WEEK('2024-03-01') → 9 |
| DAY | 주어진 날짜에서 일을 추출하는 함수 | DAY('2024-03-01') → 1 |
| HOUR | 시간에서 시(Hour)를 추출하는 함수 | HOUR('2024-03-01 12:34:56') → 12 |
| MINUTE | 시간에서 분(Minute)을 추출하는 함수 | MINUTE('2024-03-01 12:34:56') → 34 |
| SECOND | 시간에서 초(Second)를 추출하는 함수 | SECOND('2024-03-01 12:34:56') → 56 |
| MILLISECOND | 시간에서 밀리초(Millisecond)를 추출하는 함수 | MILLISECOND('2024-03-01 12:34:56.123') → 123 |
| DAY_OF_YEAR | 날짜에서 해당 연도의 몇 번째 날인지 추출하는 함수 | DAY_OF_YEAR('2024-03-01') → 61 |
| DAY_OF_WEEK | 날짜에서 해당 주의 몇 번째 날(=요일(1=Sunday, 7=Saturday))인지추출하는 함수 | DAY_OF_WEEK('2024-03-01') → 5 |
| DATE_TRUNC | - 날짜를 지정된 단위로 잘라서 반환하는 함수 - 연도 단위로 자름; 해당 연도의 첫날을 반환(1월 1일) - 월 단위로 자름; 해당 달의 첫날을 반환(1일) - 주 단위로 자름; 해당 주의 첫날(월요일)을 반환 - 일 단위로 자름; 해당 날짜의 00:00:00을 반환 |
- DATE_TRUNC('year', '2024-09-15') → 2024-01-01 - DATE_TRUNC('month', '2024-09-15') → 2024-09-01 - DATE_TRUNC('week', '2024-09-15') → 2024-09-09 - DATE_TRUNC('day', '2024-09-15 14:35:50') → 2024-09-15 00:00:00 |
| DATE_ADD | 날짜에 지정된 기간을 더하는 함수 | DATE_ADD('month', 1, '2024-03-01') → 2024-04-01 |
| DATE_DIFF | 두 날짜 사이의 차이를 반환하는 함수 (기본 단위 : 'day') | - DATE_DIFF('2024-03-01', '2024-02-28') → 2 - DATE_DIFF('year', '2024-03-01', '2023-03-01') → 1 - DATE_DIFF('quarter', '2024-03-01', '2023-03-01') → 4 - DATE_DIFF('month', '2024-03-01', '2023-03-01') → 12 - DATE_DIFF('week', '2024-03-01', '2024-02-01') → 4 - DATE_DIFF('day', '2024-03-01', '2024-02-28') → 2 - DATE_DIFF('hour', '2024-03-01 12:00:00', '2024-02-28 12:00:00') → 24 - DATE_DIFF('minute', '2024-03-01 12:00:00', '2024-02-28 12:00:00') → 1440 - DATE_DIFF('second', '2024-03-01 12:00:00', '2024-02-28 12:00:00') → 86400 - DATE_DIFF('millisecond', '2024-03-01 12:00:00', '2024-02-28 12:00:00') → 86400000 |
| DATE_FORMAT | 날짜 및 시간을 특정 형식으로 변환하는 함수 | - DATE_FORMAT('2024-03-01', '%Y-%m-%d') → 2024-03-01 - DATE_FORMAT(NOW(), '%H:%i:%s') → 02:15:30 - DATE_FORMAT(NOW(), '%r') → 02:15:30 PM - DATE_FORMAT(NOW(), '%T') → 14:15:30 |
| CURRENT_DATE | 현재 날짜를 반환하는 함수 | CURRENT_DATE() → 2024-03-01 |
| CURRENT_TIME | 현재 시간을 반환하는 함수 | CURRENT_TIME() → 12:34:56 |
| CURRENT_TIMESTAMP | 현재의 날짜와 시간을 타임스탬프 형식으로 반환 | CURRENT_TIMESTAMP() → 2024-03-01 12:34:56 |
| DATE_PARSE | - 문자열을 날짜로 변환하는 함수 ① 날짜만 제공되면 시간은 기본적으로 00:00:00으로 채워짐 ② 시간만 제공되면 기본 날짜는 1970-01-01로 설정됨 (Unix Epoch) ③ 날짜와 시간이 모두 제공된 경우, 해당 날짜와 시간으로 반환됨 |
① DATE_PARSE('2024-03-27', '%Y-%m-%d') → 2024-03-27 00:00:00 ② DATE_PARSE('23:58:59', '%H:%i:%s') → 1970-01-01 23:58:59 ③ DATE_PARSE('2024-06-28 15:23:23', '%Y-%m-%d %H:%i:%s') → 2024-06-28 15:23:23 |
3. 윈도우 함수
1) 정의
- GROUP BY와 유사하게 특정한 그룹에 대해 집계(계산을 통해 요약)를 하는 함수
- GROUP BY가 테이블의 형태를 변화시키는 것과 달리, 윈도우 함수는 원래의 테이블 구조를 유지하면서, 각 행에 대해 집계 결과를 추가
2) 윈도우 함수 종류
- 순위
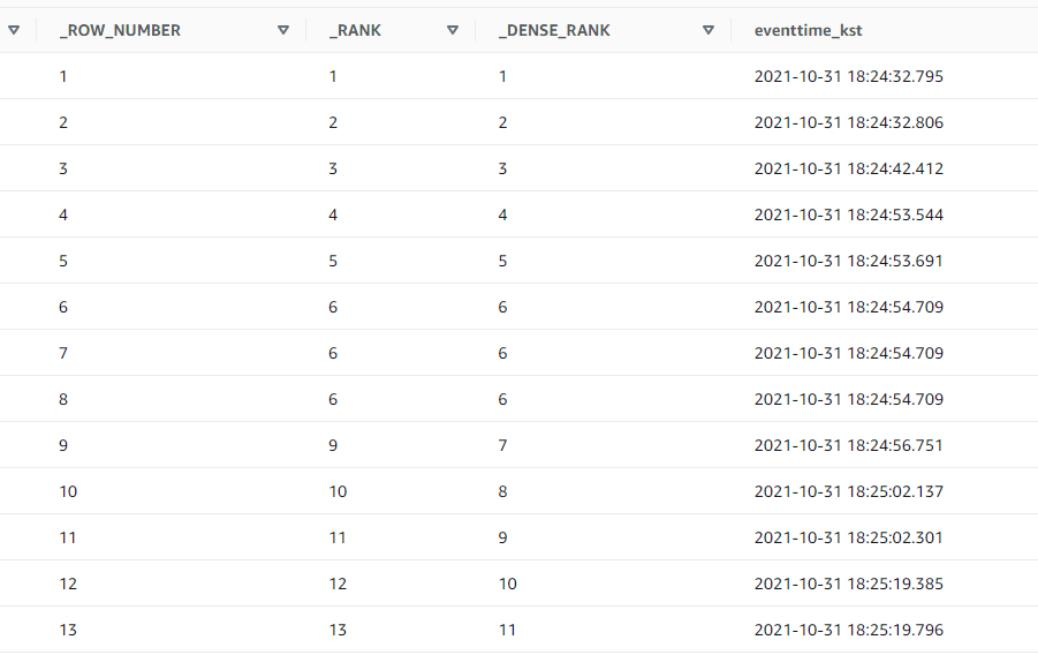
| 함수명 | 설명 | 예시 (값 기준으로 순위 매기기) |
| RANK | 동일한 값에는 같은 순위를 부여하지만, 그 다음 순위는 건너뜀 | 예시: 1, 1, 2 → 1, 1, 3 |
| DENSE_RANK | 동일한 값에는 같은 순위를 부여하고, 그 다음 순위는 연속적으로 부여됨 | 예시: 1, 1, 2 → 1, 1, 2 |
| ROW_NUMBER | 각 행에 고유한 순위를 부여하며, 동일한 값이라도 고유 번호가 부여됨 | 예시: 1, 1, 2 → 1, 2, 3 |
4. JOIN
1) 정의
- JOIN : SQL에서 두 개 이상의 테이블을 결합하여 데이터를 조회할 때 사용하는 기능
- 두 테이블을 연결해서, 관련된 데이터를 한꺼번에 볼 수 있게 함
- 테이블을 연결할 때는 공통된 컬럼을 기준으로 사용
2) JOIN의 종류
- INNER JOIN: 두 테이블에서 공통된 값이 있는 행만 결합
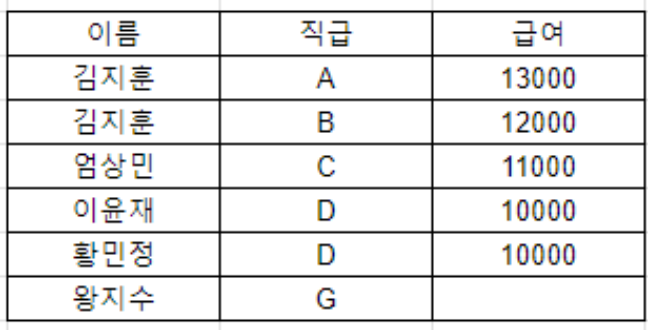
- LEFT JOIN: 왼쪽 테이블의 모든 행을 반환하고, 오른쪽 테이블에 일치하는 데이터가 없으면 NULL을 반환
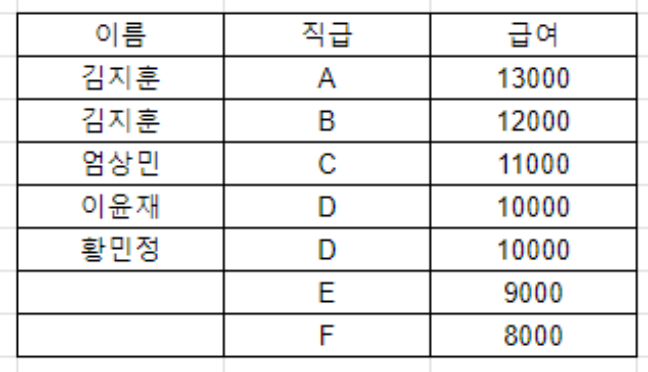
- RIGHT JOIN: 오른쪽 테이블의 모든 행을 반환하고, 왼쪽 테이블에 일치하는 데이터가 없으면 NULL을 반환
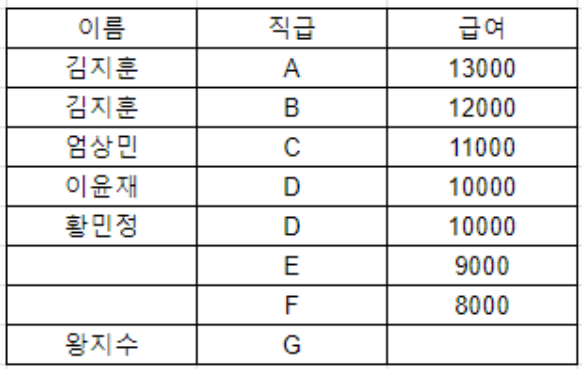
- OUTER JOIN: 두 테이블의 모든 행을 반환하고, 일치하는 데이터가 없는 경우에는 NULL을 반환
- CROSS JOIN: 두 테이블의 모든 가능한 조합을 생성하는 것이므로, 결과 행의 개수는 두 테이블 행의 개수의 곱이 됨
- SELF JOIN: 같은 테이블을 자기 자신과 조인. 같은 테이블의 다른 행을 서로 비교하거나, 테이블 내에서 관련된 데이터를 결합(같은 테이블을 두 번 사용하는 것이므로, 하나의 테이블에 대해 두 개의 별칭(alias)을 주고 조인)

3) 종류별 예시

① INNER JOIN

② LEFT JOIN
③ RIGHT JOIN
④ OUTER JOIN
⑤ CROSS JOIN

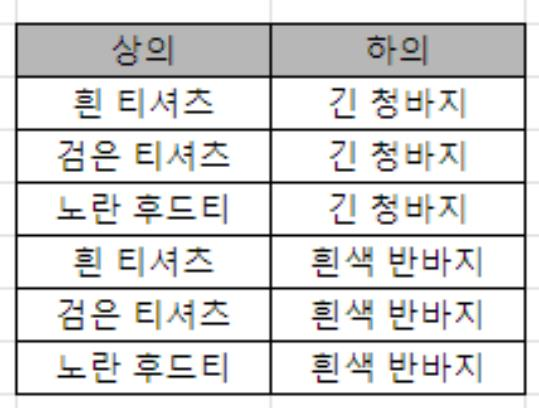
5. UNION; 두 개 이상의 데이터를 합하는 또다른 방법
1) 정의
① UNION (DISTINCT)

- 두 개 이상의 쿼리 결과를 결합하는 데 사용
- 각 SELECT 문에서 반환되는 데이터를 결합하여 최종 결과를 만듦
- 각 쿼리의 열 수와 데이터 타입이 동일해야 함
- 중복된 데이터는 제거하고, 고유한 데이터만 반환
- 중복 제거 과정이 추가되기 때문에 UNION ALL 보다 느릴 수 있음
② UNION ALL
- 중복된 데이터를 포함하여 모든 결과를 반환
2) 사용 예시
-- UNION
SELECT name FROM employees
UNION
SELECT name FROM customers;
-- UNION ALL
SELECT name FROM employees
UNION ALL
SELECT name FROM customers;
6. WITH
1) 정의
- WITH 문 : 하위 쿼리(서브 쿼리)를 재사용 가능한 가상의 테이블로 정의하여, 이를 메인 쿼리에서 활용할 수 있게 함
2) 사용 이유
- 가독성: 복잡한 쿼리를 단순화하고 분리하여, 쿼리의 각 부분이 쉽게 이해되도록 작성할 수 있음
- 재사용성: 한 번 정의한 가상의 테이블(CTE; Common Table Expression)을 여러 번 참조할 수 있어 반복적인 서브쿼리를 피할 수 있음
- 성능 최적화: 서브쿼리를 한 번만 실행하고 그 결과를 재사용할 수 있어, 성능 개선이 가능
3) 사용 예시
-- 1. 사원 테이블에서 상위 급여를 가진 사원 찾기
-- WITH high_salary AS (...): high_salary라는 가상의 테이블을 생성하여 급여가 5000 이상인 사원을 저장
-- 메인 쿼리에서 이 가상의 테이블을 직접 참조하여 employee_id와 name을 조회
WITH high_salary AS (
SELECT employee_id, name, salary
FROM employees
WHERE salary > 5000
)
SELECT employee_id, name
FROM high_salary;
-- 2. 여러 CTE 사용 예시
-- 첫 번째 total_sales CTE에서 각 상점의 총 판매량을 계산
-- 두 번째 average_sales CTE에서 전체 상점의 평균 판매량을 계산
-- 메인 쿼리에서는 총 판매량이 평균을 초과하는 상점을 선택하여 조회
WITH total_sales AS (
SELECT store_id, SUM(sales) AS total
FROM sales
GROUP BY store_id
),
average_sales AS (
SELECT AVG(total) AS avg_sales
FROM total_sales
)
SELECT store_id, total
FROM total_sales
WHERE total > (SELECT avg_sales FROM average_sales);
📘 쿼리 실습
1. SQL 쿼리문 작성
1) 문자열 처리
① 대소문자 변환
SELECT UPPER('abc'); SELECT UPPER('가나다'); SELECT UPPER('Abc'); SELECT LOWER('Abc');
② 문자열 자르기SELECT SUBSTRING('ABC', 2); -- 2번째 문자열 ~ 끝까지 출력 SELECT SUBSTRING('CHUNJAE EDUCATION', 9, 3); -- 9번째 문자열 ~ 3개 출력 SELECT SUBSTRING('CHUNJAE EDUCATION', -3, 3); -- 뒤에서 3번째 ~ 3개 출력
③ 문자열 위치 찾기SELECT POSITION('T' IN 'XTZ'); SELECT POSITION('T' IN ' TZ'); -- 공백도 문자 하나로 취급 SELECT POSITION('T' IN 'TZT'); -- 같은 문자가 두번 이상 올 경우, 왼쪽 기준으로 가장 먼저 오는 문자를 선택
④ 문자열 결합/대체SELECT CONCAT('abc', '123'); -- 두 문자열을 결합 SELECT 'abc' || 'xyz'; -- ||는 CONCAT과 동일한 기능 SELECT REPLACE('TEXTBOOK', 'X', 'SG'); -- X를 SG로 대체 SELECT REPLACE('TEXTBOOK', 'X', ''); -- X를 빈 문자열로 대체
⑤ 패딩 (문자열 길이 채우기)SELECT LPAD('abc', 5, 'x'); -- 왼쪽에 x를 채워 길이를 5로 맞춤 SELECT RPAD('abc', 6, 'xyz'); -- 오른쪽에 xyz를 순환적으로 채워 길이를 6으로 맞춤
⑥ 문자열 길이 반환SELECT LENGTH('CHUNJAE EDUCATION'); -- 문자열 길이를 반환
2) 수학 함수 및 연산
① 절대값, 올림/내림
SELECT ABS(-3.14); -- 절대값 SELECT CEILING(3.14); -- 올림 SELECT FLOOR(3.14); -- 내림
② 반올림, 자르기SELECT ROUND(-3.141592, 2); -- 소수점 2자리까지 반올림 SELECT TRUNCATE(3.141592); -- 소수점 이하를 버림
③ 나머지, 몫SELECT 5/2; -- 나눈 값(2.5, 실수); 일부 SQL 엔진(ex: SQL Server)에서는 정수와 정수의 연산에 대한 결과값을 정수로 반환 -- 정수 나눗셈 결과를 실수로 반환하고 싶은 경우, 어느 한쪽에 1.0을 곱하거나∙CAST 함수를 이용하여 데이터 타입 변환(FLOAT)을 거친 뒤 나눗셈(/)을 수행 SELECT 5 DIV 2; -- 몫(2, 정수) SELECT MOD(5, 2); -- 나머지(1) SELECT 5%2; -- 나머지(1)
④ 제곱SELECT POWER(-3.141592, 3); -- 제곱 연산
3) 날짜 및 시간 처리
① 현재 날짜/시간 출력
SELECT NOW() AS "현재", YEAR(NOW()) AS "연도", QUARTER(NOW()) AS "분기", MONTH(NOW()) AS "월", DAY(NOW()) AS "일";
② 날짜 차이 계산SELECT DATE_DIFF('year', DATE_ADD('year', 1, NOW()), NOW()); -- 연도 차이 계산 SELECT DATE_DIFF('month', DATE_ADD('month', 1, NOW()), NOW()); -- 월 차이 계산
③ 날짜 형식 변환SELECT DATE_FORMAT(NOW(), '%Y-%m-%d'); -- 날짜 형식 변환 SELECT DATE_PARSE('2024-10-02', '%Y-%m-%d'); -- 문자열을 날짜 형식으로 파싱
4) 데이터 처리 및 변환
① 데이터 정렬/제한
SELECT * FROM "learning_analytics"."e_assessment" LIMIT 5; -- 해당 쿼리는 실행할 때마다 LIMIT 5가 반환하는 상위 5개 행이 달라짐; 쿼리에서 정렬이 지정되어 있지 않기 때문 -- 항상 동일한 결과를 얻고 싶다면, ORDER BY 를 추가 SELECT "proc_ymd", SUBSTRING("proc_ymd", -2) FROM "learning_analytics"."e_assessment" LIMIT 5;
② 정수/실수 변환 및 연산SELECT ROUND("video_jump_cnt" * 1.0 / "media_action_cnt", 2) AS "jump_rate" -- 실수 변환
5) 데이터 타입 변경
① 데이터 형식 변환
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s'); -- 날짜를 문자 형식으로 변환 SELECT CAST(NOW() AS VARCHAR); -- 날짜를 VARCHAR 형식으로 변환 SELECT CAST(CAST(NOW() AS VARCHAR) AS TIMESTAMP); -- VARCHAR를 TIMESTAMP로 다시 변환
② 문자열 자르기 + 대문자 변환SELECT "userid", UPPER(SUBSTRING("userid", -12)) -- userid 뒷부분 대문자 변환
③ 정규 표현식 사용SELECT "userid", UPPER(REGEXP_EXTRACT("userid", '[a-zA-Z0-9]{12}')) -- 정규 표현식으로 문자열 추출 후 변환
6) 윈도우 함수
① 기본 윈도우 함수
SELECT ROW_NUMBER() OVER(PARTITION BY "userid" ORDER BY "eventtime_kst" ASC) AS "_row_number" FROM "learning_analytics"."e_learning_action" LIMIT 5;② 누적 합계 계산
SELECT *, SUM("sum_point") OVER (PARTITION BY "userid" ORDER BY "proc_ymd" ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS "total_sum" FROM ( SELECT "proc_ymd", "userid", SUM("point") AS "sum_point" FROM "learning_analytics"."e_point" WHERE "point" > 0 GROUP BY "proc_ymd", "userid" );
7) JOIN
① INNER JOIN
SELECT "proc_ymd", "userid", "mcode", "ea"."score", "ead"."no", "ead"."answer", "ead"."correct" FROM "learning_analytics"."e_assessment" AS "ea" INNER JOIN "learning_analytics"."e_assessment_detail" AS "ead" ON "ea"."userid" = "ead"."userid";② LEFT JOIN
SELECT "A"."이름", "A"."직급", "B"."급여" FROM "A" LEFT JOIN "B" ON "A"."직급" = "B"."직급";
8) UNION
① UNION/UNION ALL
SELECT "proc_ym", COUNT(*) AS "cnt", 'e_learning_action' AS "table_name" FROM "learning_analytics"."e_learning_action" GROUP BY "proc_ym" UNION ALL SELECT "proc_ym", COUNT(*) AS "cnt", 'e_learning_time' AS "table_name" FROM "learning_analytics"."e_learning_time" GROUP BY "proc_ym";
📙 내일 일정
- 자연어 처리() 학습

'TIL _Today I Learned > 2024.10' 카테고리의 다른 글
| [DAY 59] 자연어 처리 (NLP) (2) | 2024.10.14 |
|---|---|
| [DAY 58] 자연어 처리 (NLP) (1) | 2024.10.11 |
| [DAY 57] SQL 실습 (1) | 2024.10.10 |
| [DAY 56] 비관계형 데이터베이스 (1) | 2024.10.08 |
| [DAY 55] SQL의 응용 (1) | 2024.10.07 |



