[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.07.23
📕 학습 목록
- 데이터 요약하기
- 데이터 합치기
- 시각화 라이브러리
- 시각화 구성요소
- 관계형 시각화
📗 기억할 내용
1. Data Preprocessing
1) 데이터 요약하기
① 데이터 그룹화
- groupby() 메서드 : 데이터를 그룹별로 분할, 적용, 결합함
- 분할(Split) : 데이터를 특정 기준에 따라 여러 그룹으로 분할
- 적용(Apply) : 각 그룹에 대해 하나 이상의 함수(통계 요약, 변환, 필터링 등)를 적용하여 결과를 얻음
- 결합(Combine) : 모든 함수 적용 결과를 하나의 데이터 구조로 결

② 기본 사용법
- df.groupby('컬럼명').통계 함수() : 특정 그룹에 통계 함수를 적용
# 단일 열 기준 그룹화
grouped = df.groupby('column1')
# 복수 열 기준 그룹화
grouped = df.groupby(['column1', 'column2'])
# 평균 계산
grouped.mean()
# 합계 계산
grouped.sum()
# 카운트
grouped.count()
# 최대값
grouped.max()
# 최소값
grouped.min()- [Ex] 부서별로 평균 급여 확인하기
# 부서별로 그룹화
grouped = df.groupby("Department")
# 부서별로 평균 급여 계산
average_salary = grouped["Salary"].mean()
print(average_salary)
③ groupby 응용
- 다중 집계 함수 : agg()
- 그룹별로 집계(aggregation) 연산시 사용
- 여러 함수(or 사용자 정의 함수)를 동시에 데이터에 적용할 수 있음
# 부서별 급여에 대한 여러 집계 함수 적용
dept_salary_summary = df.groupby("Department")["Salary"].agg(["sum", "mean", "min", "max"])
print(dept_dalary_summary)
# 여러 열에 대해 각각 함수 적용
result = df.groupby("Department").agg(
{
"Name": "count",
"Age": "mean",
"Salary": ["mean", "min", "max"]
}
)
print(result)
- 사용자 정의 함수 : apply()
- 그룹화된 데이터에 대해 복잡한 변환/연산을 수행할 때 사용
- 각 그룹에 함수를 적용 → 그 결과를 pandas 객체로 반환
# 사용자 정의 함수 : 최대 급여 - 최소 급여 차이 계산
def salary_range(group):
return group["Salary"].max() - group["Salary"].min()
salary_diff = df.groupby("Department").apply(
salary_range,
include_groups=False, # 사용자 정의 함수를 그룹 단위로 적용할 때, 그룹 정보(그룹 라벨)을 함수에 전달x
)
print(salary_diff)[TIP] agg vs apply
* agg
- 간단한 집계 연산에 사용
- 각 열에 대해 독립적으로 함수를 적용
* apply
- 더 복잡하거나 사용자 정의 연산에 사용
- 그룹 전체에 함수를 적용할 수 있음
- Group 필터링 : filter() 메서드
- 특정 조건을 만족하는 그룹만 선택
- 각 그룹에 대해 boolean 값을 반환하는 함수를 인자로 받음
- 함수가 True를 반환하는 그룹만 결과 데이터셋에 포함됨
# filter 사용 예시
# 직원수 2명 초과인 부서만 선택
def greater_count(group):
condition = group["Name"].count() > 2
return condition
filter_departments = df.groupby("Department").filter(greater_count)
print(filter_departments)
# 평균 급여가 70000 이상인 부서만 선택
def greater_salary(group):
return group["Salary"].mean() >= 70000
filter_departments = df.groupby("Department").filter(greater_salary)
print(filter_departments)
2) 데이터 합치기
① 데이터 프레임 연결하기
- concat : 열 방향 or 행 방향으로 여러 테이블을 연결
- merge : 특정 기준에 따라 테이블을 병합
- pd.concat
- 리스트 형태로 여러 데이터 프레임을 받아 병합 → 새로운 데이터 프레임 생성
pd.concat([df1, df2, df3,...])
- 행 or 열 방향으로 병합 방향을 지정(axis=0 or 1); 기본값은 행 방향(axis=0)
# 행 방향 데이터 프레임 병합
df1 = pd.DataFrame(
{
"A": ["A0", "A1"],
"B": ["B0", "B1"],
}
)
df2 = pd.DataFrame(
{
"A": ["A2", "A3"],
"B": ["B2", "B3"],
}
)
new_df = pd.concat([df1, df2], ignore_index=True) # ignore_index=True : 인덱스를 0부터 재설정
print(new_df)
"""
A B
0 A0 B0
1 A1 B1
2 A2 B2
3 A3 B3
"""# 열 방향 데이터 프레임 병합
new_df = pd.concat([df1, df2], axis=1)
print(new_df)
"""
A B A B
0 A0 B0 A2 B2
1 A1 B1 A3 B3
"""
② 테이블 조인
: 특정 기준(하나 이상의 키)에 따라 데이터 프레임을 병합
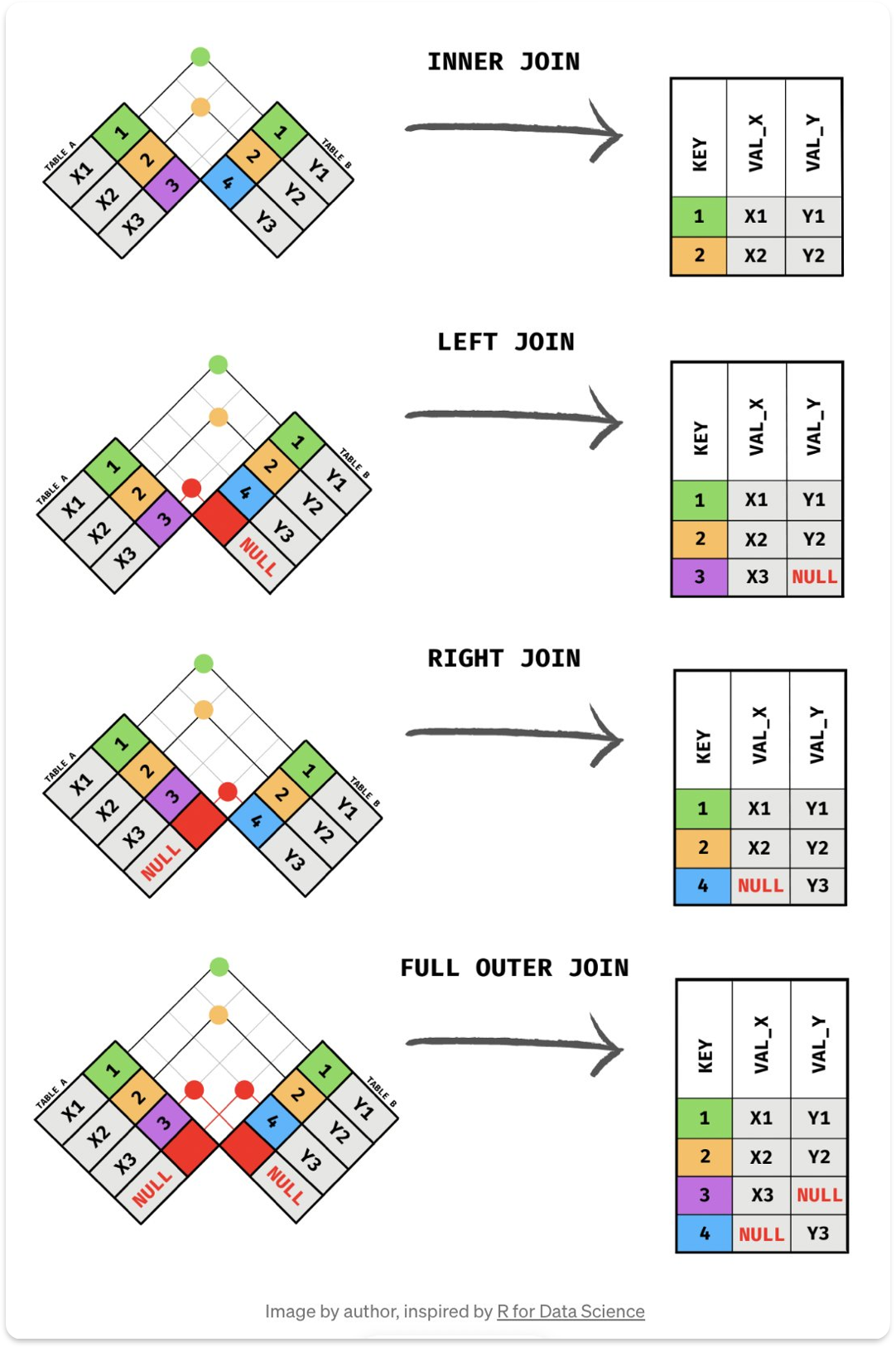
: 기본 사용법
pd.merge(left_df, right_df, on="병햡 기준 열", how="병합 방법")- Join 종류
- Inner Join : 두 데이터 프레임에 모두 존재하는 기준 열에 대해 병합 how='inner'
- Outer Join : 두 데이터 프레임에 존재하는 모든 열에 대해 병합 how='left'
- Left Join : 왼쪽 데이터 프레임's 열을 기준으로 병합 how='right'
- Right Join : 오른쪽 데이터 프레임's 열을 기준으로 병합 how='outer'
# Inner Join
df_left = pd.DataFrame(
{
"Key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
df_right = pd.DataFrame(
{
"Key": ["K0", "K1", "K2", "K4"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
inner_joined_df = pd.merge(
df_left,
df_right,
how="inner", # 병합 방법 : inner
on="Key", # 병합 기준 열 : Key
)
print(inner_joined_df)
"""
Key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
"""# Outer Join
outer_joined_df = pd.merge(
df_left,
df_right,
how="outer", # 병합 방법 : outer
on="Key",
)
print(outer_joined_df)
"""
Key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN
4 K4 NaN NaN C3 D3
"""# Left Join
left_joined_df = pd.merge(
df_left,
df_right,
how="left", # 병합 방법 : left
on="Key",
)
print(left_joined_df)
"""
Key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN
"""# Right Join
right_joined_df = pd.merge(
df_left,
df_right,
how="right", # 병합 방법 : right
on="Key",
)
print(right_joined_df)
"""
Key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K4 NaN NaN C3 D3
"""
2. Data Visualization
1) 시각화 라이브러리
| matplotlib | seaborn | plotly | |
| 주요 용도 | 기본적인 플로팅 및 커스터마이징 | 통계적 시각화 및 고급 스타일링 | 대화형 시각화 및 웹 기반 시각화 |
| 복잡도 | 중간 (기본 그래프는 쉬우나, 고급 기능은 복잡) | 쉬움 (기본 플롯은 간단하고 직관적) | 쉬움~중간 (복잡한 대화형 플롯 지원) |
| 커스터마이징 | 매우 유연함 (세부 조정 가능) | 한정적 (기본 스타일에 충실) | 유연하지만 기본 설정이 좋음 |
| 대화형 기능 | 없음 (기본적으로 정적 그래프) | 없음 (정적 그래프, 일부 인터랙티브 기능 가능) | 있음 (줌, 팬, 툴팁 등 대화형 기능 포함) |
| 기본 스타일 | 단순함 (디자인적 요소는 기본 제공) | 세련되고 미리 정의된 스타일 | 현대적이고 시각적으로 매력적 |
| 사용자 커뮤니티 | 매우 크고 활발함 | 활발함 (matplotlib에 비해 작음) | 빠르게 성장 중 |
| 사용 시나리오 | 세부 조정이 필요한 경우 | 통계 분석 및 시각화 | 대화형 그래프가 필요한 경우 |
| 의존성 | 단일 라이브러리로 독립적 사용 가능 | matplotlib에 의존 | 별도 의존성 적음 (웹 기반 시각화용) |
| 배포 용이성 | 정적 이미지로 다양한 포맷 저장 가능 | 정적 이미지로 저장 가능 | HTML로 내보내기 쉬움 (대화형 요소 유지) |
| 학습 곡선 | 중간 (기능 많고 복잡함) | 낮음 (친숙한 API 제공) | 중간 (대화형 기능 학습 필요) |
| 지원하는 플롯 종류 | 거의 모든 플롯 지원 | 주로 통계적 시각화와 고급 플롯 지원 | 거의 모든 플롯 지원 + 3D 플롯 |
2) 시각화 구성요소
① 그래프 구성요소
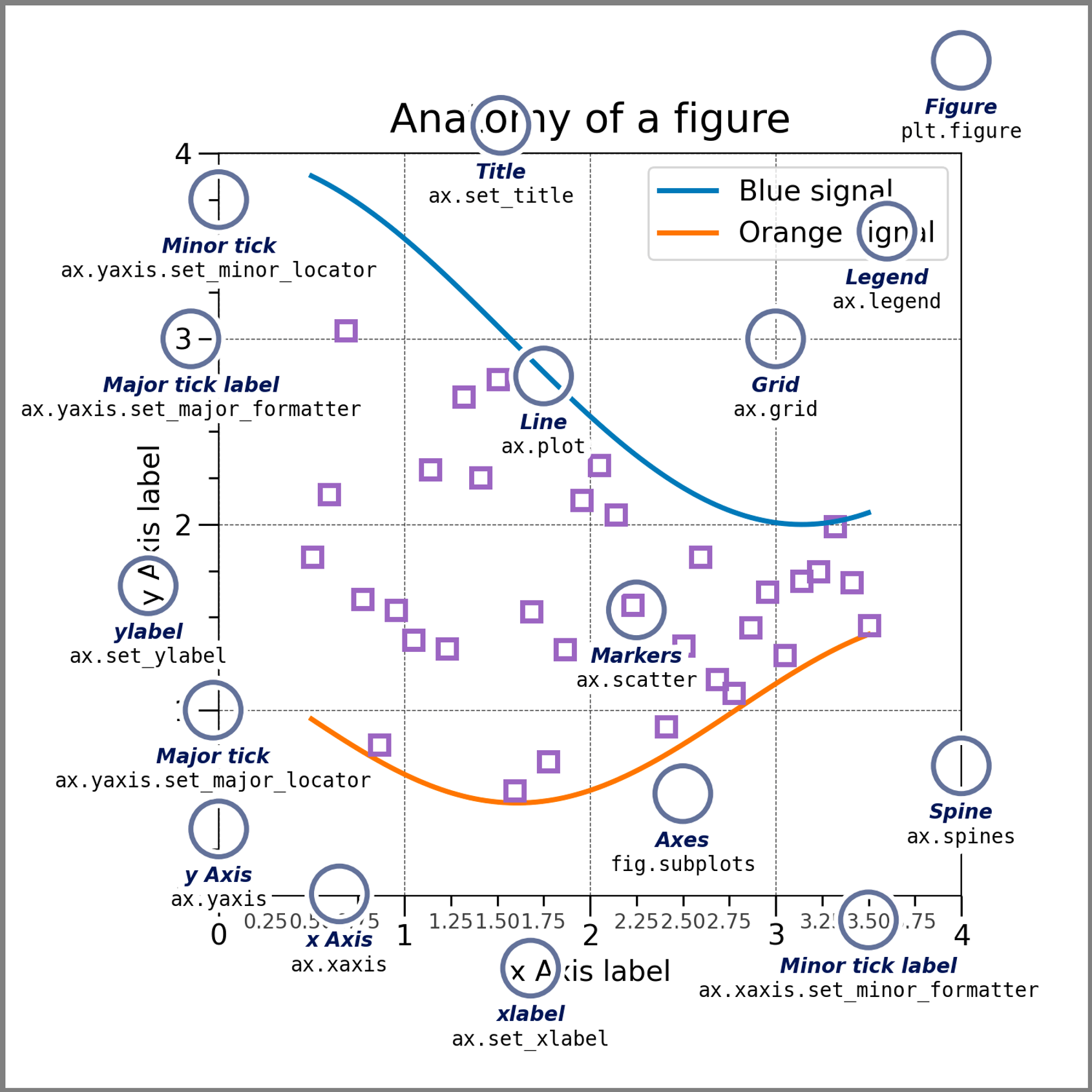
- Figure : 전체 그래프의 컨테이너역할. 하나의 Figure는 여러개의 Axes를 가질 수 있음
- Axes : 실제 데이터가 시각화 되는 공간
- pyplot : pyplot 객체(⊂matplotlib 라이브러리)를 통해 더 쉽게 그래프를 생성∙설정∙출력할 수 있음
# pyplot 객체로 Line Plot 그리기
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 기본 Line Plot
plt.plot(x, y, label="y")
# 타이틀 설정
plt.title("Line Plot")
# 라벨 설정
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
# 범례 표시
plt.legend()
# 그래프 출력
plt.show()
# plt.subplots() : Figure 1개 - Axes 1개
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y_line = [10, 20, 25, 30, 40]
# 한 개의 Figure 와 한 개의 Axes 생성
fig, ax = plt.subplots(figsize=(12, 10))
ax.plot(x, y_line, color="r", label="y")
ax.set_xlabel("X-axis")
ax.set_ylabel("Y-axis")
ax.legend()
# Axes 타이틀 설정
ax.set_title("Line Plot Axes")
# Figure 타이틀 설정
fig.suptitle("1 Figure 1 Axes")
# 그래프 출력
plt.show()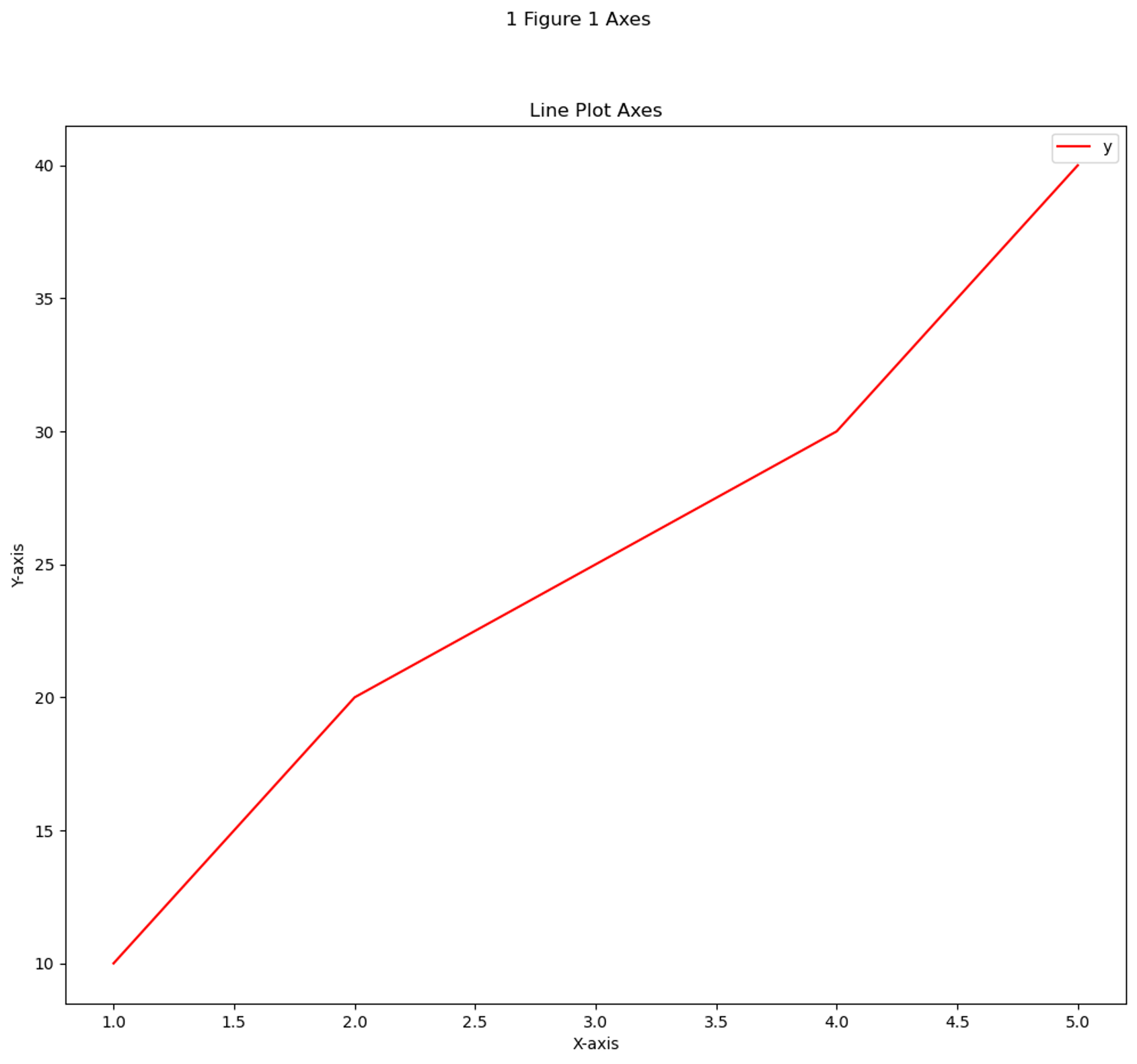
# plt.subplots() : Figure 1개 - Axes 4개
import matplotlib.pyplot as plt
# 데이터 준비
x = [1, 2, 3, 4, 5] # x축 데이터
y_scatter = [10, 20, 25, 30, 40] # scatter plot 데이터
y_line = [8, 15, 22, 29, 36] # line plot 데이터
bar_heights = [5, 7, 9, 11, 13] # bar plot 데이터
# 한 개의 Figure 와 네 개의 Axes 생성
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
# 첫 번째 Axes에 bar plot 생성
ax1.bar(x, bar_heights, color="g")
ax1.set_title("bar plot")
# 두 번째 Axes에 scatter plot 생성
ax2.scatter(x, y_scatter, color="r")
ax2.set_title("scatter plot")
# 세 번째 Axes에 line plot 생성
ax3.plot(x, y_line, color="b")
ax3.set_title("line plot")
# Figure 대한 타이틀설정
fig.suptitle("1 Figure 4 Axes")
# 그래프 간격을 자동으로 조정
plt.tight_layout()
# 그래프 출력
plt.show()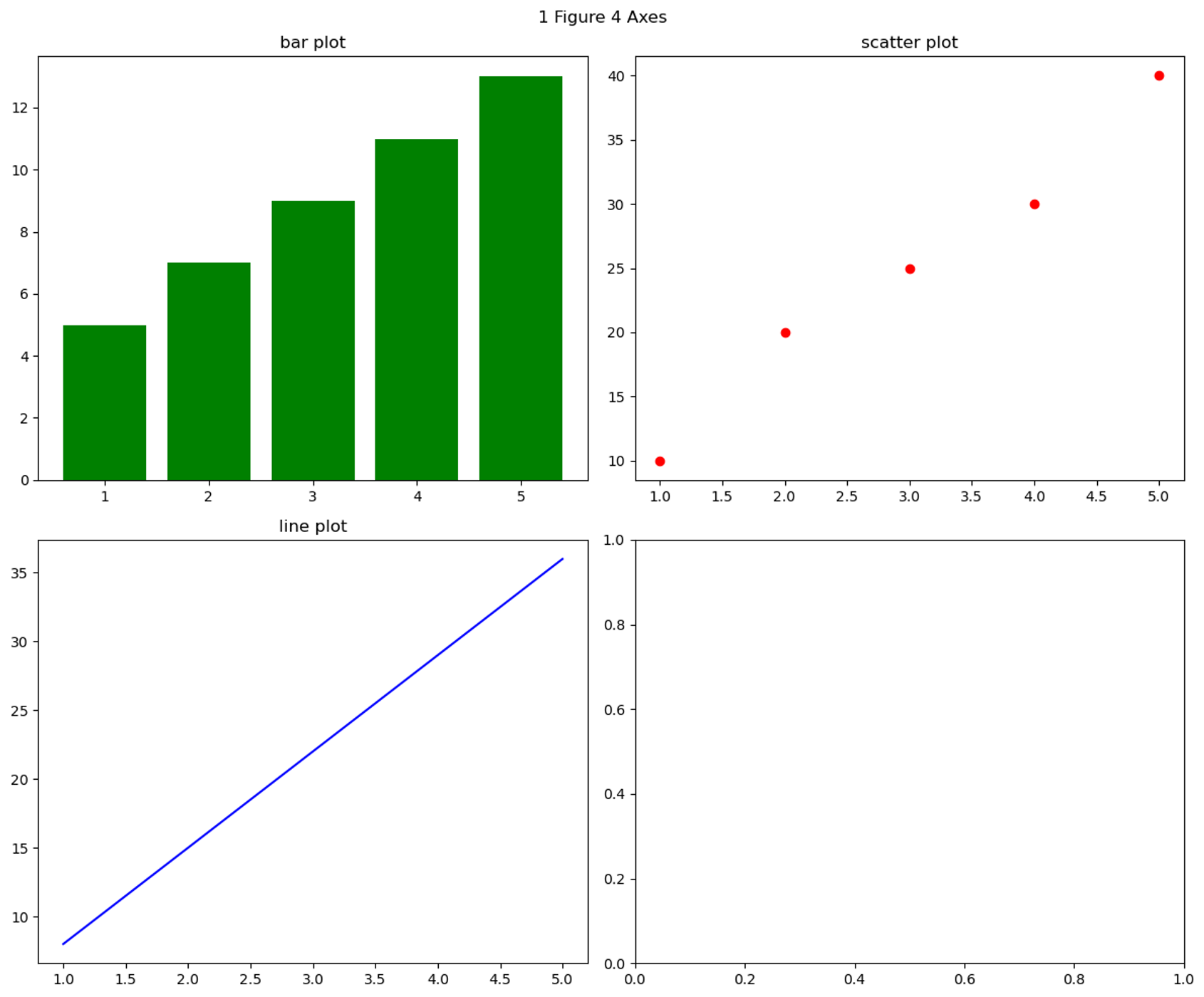
② 그래프 커스터마이즈
- Figure, Axe 객체 세트 생성
plt.subplot(nrows=행, ncols=열, figsize=(가로, 세로))
# nrows, ncols : 다중 subplot을 행, 열 형태로 생성
# figsize : Figure 크기 설정- 그래프 제목 설정
plt.title('제목', fontsize=폰트 크기)- 축 레이블 설정
plt.xlabel('x축 레이블', fontsize=폰트 크기)
plt.ylabel('y축 레이블', fontsize=폰트 크기)- 범례 표시
plt.legend(['범례1', '범례2'])- 축 범위 설정
# x축 범위 지정
plt.xlim([최소값, 최대값])
# y축 범위 지정
plt.ylim([최소값, 최대값])- 눈금 설정
# x축 눈금 설정
plt.xticks([눈금 리스트], rotation=눈금 회전 각도)
# y축 눈금 설정
plt.yticks([눈금 리스트])- 그리드 표시
# 그래프에 그리드 표시
plt.grid(True)- 텍스트 추가
# 그래프 특정 위치에 텍스트 추가
plt.text(x, y, '텍스트')- 주석 추가
# 그래프에 주석 추가 & 화살표로 특정 위치 가리킴
plt.annotate('주석', xy=(x, y), xytext=(x_offset, y_offset), arrowprops=dict(facecolor='black'))
# xy : 주석 추가할 데이터 좌표(화살표가 가리킬 좌표)
# xytext : 텍스트를 표시할 좌표
# arrowprops : 화살표 속성(주석-데이터 포인트를 연결하는 화살표 스타일)- 그래프 그리기
plt.show()
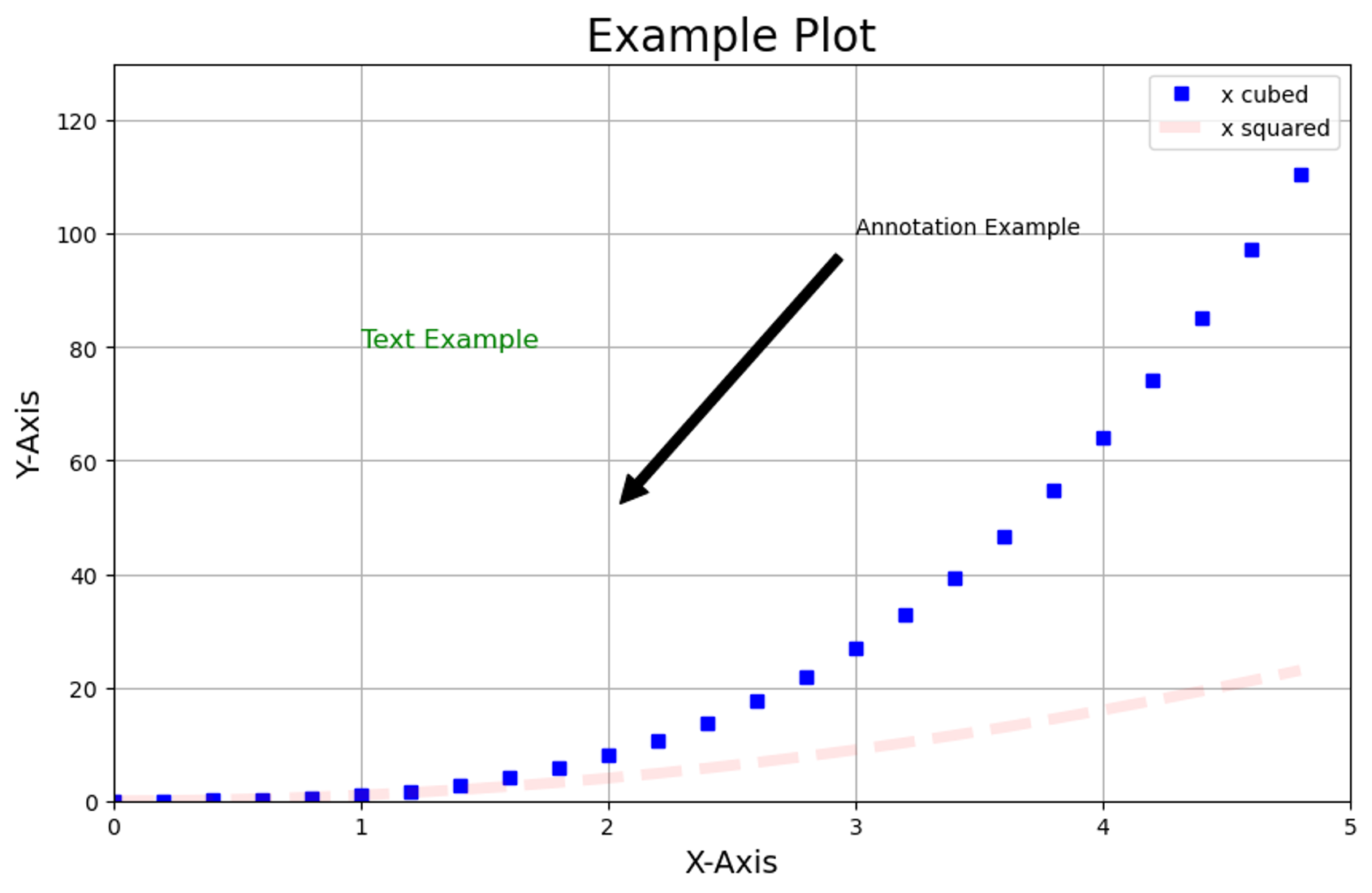
# 그래프 그리기 예시
import matplotlib.pyplot as plt
import numpy as np
# 그래프 데이터 생성
x = np.arange(0.0, 5.0, 0.2)
y1 = x**2
y2 = x**3
# 그래프 크기 조절
plt.figure(figsize=(10, 6))
# 두 개의 선 그래프 그리기
plt.plot(x, y2, "bs", label="x cubed") # 파란색 사각형, 세제곱
plt.plot(
x, # x 축 데이터
y1, # y 축 데이터
linestyle="--", # 선 스타일
linewidth=5, # 선 너비
color="r", # 선 색깔
alpha=0.1, # 선 투명도
label="x squared", # 범례 레이블
) # 빨간색 점선, 제곱
# 제목 및 축 레이블 설정
plt.title("Example Plot", fontsize=20)
plt.xlabel("X-Axis", fontsize=14)
plt.ylabel("Y-Axis", fontsize=14)
# 범례 표시
plt.legend()
# 축 범위 설정
plt.xlim(0, 5)
plt.ylim(0, 130)
# 눈금 설정
plt.xticks(np.arange(0, 6, 1))
plt.yticks(np.arange(0, 131, 20))
# 그리드 표시
plt.grid(True)
# 텍스트 추가
plt.text(1, 80, "Text Example", fontsize=12, color="green")
# 주석 추가
plt.annotate(
"Annotation Example",
xy=(2, 50),
xytext=(3, 100),
arrowprops=dict(facecolor="black", shrink=0.05),
)
# 그래프 출력
plt.show()
3) 관계형 시각화
(1) Scatter Plot
① Scatter Plot
- 산점도(Scatter Plot) : 두 변수 간의 관계를 시각화
- 각 점은 데이터 셋 내의 하나의 관측치를 나타냄
- 한 변수의 값을 x축에, 다른 변수의 값을 y축에 매핑 → 각 점의 위치를 결정
② 주요 특징
- 데이터 분포 & 관계 파악
- 이상치 확인 : 데이터의 이상치∙특이한 패턴을 식별
- 데이터 밀도 : 데이터 포인트가 특정 영역에 모여있으면, 해당 영역에서 데이터 밀도가 높다는 것
- 색상 및 크기 : 점의 색상∙크기를 다양하게 → 추가 변수의 정보를 표현
③ 한계
- 대량의 데이터 : 대량의 데이터 시각화시, 점들이 서로 겹쳐버려 데이터 분포∙패턴 파악 어려움(→ Hexbin Plot, 2D 히스토그램, KED Plot 을 고려)
- 선형성 가정 : 산점도는 두 변수 간의 선형 관계를 파악하는 데 사용됨. 비선형 관계가 있을 경우는 다른 시각화 기법을 사용하여 그 관계를 파악
④ 기본 사용법
sns.scatterplot(data, x='x축이 될 변수', y='y축이 될 변수', hue='범주가 될 변수')
⑤ 예시
# 흡연 여부에 따른 총 청구금액과 팁 금액 시각화
tips = sns.load_dataset("tips")
# 팁 금액과 총 청구금액의 연관성 시각화, 단 흡연 여부에 따라 구분
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="smoker")
plt.title("Tip Amount And Total Bill by Smoking")
plt.show()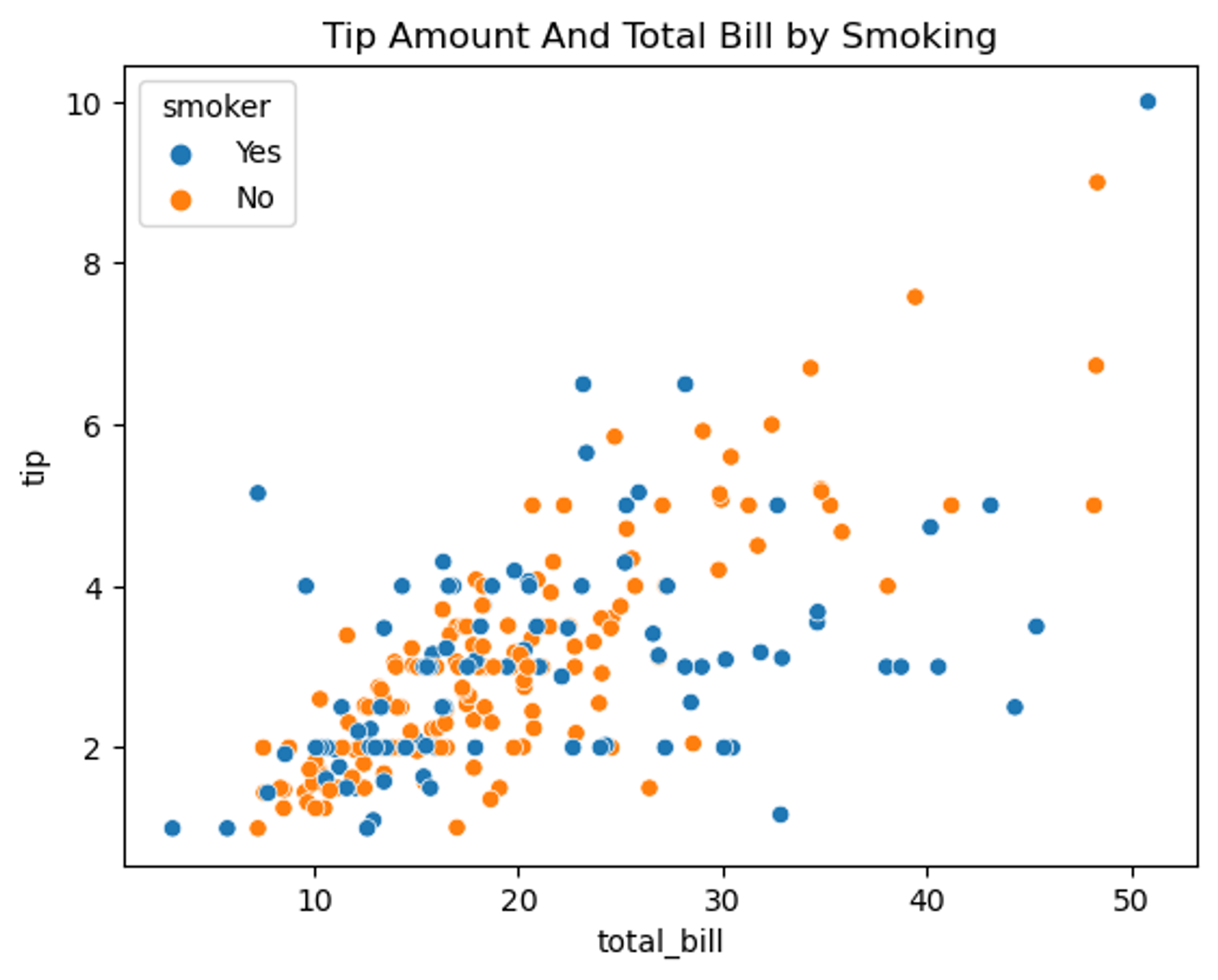
# 요일에 따른 총 청구 금액 시각화
tips = sns.load_dataset("tips")
# 요일과 총 청구금액의 연관성 시각화
sns.scatterplot(data=tips, x="day", y="total_bill")
plt.title("Total Bill by Day")
plt.show()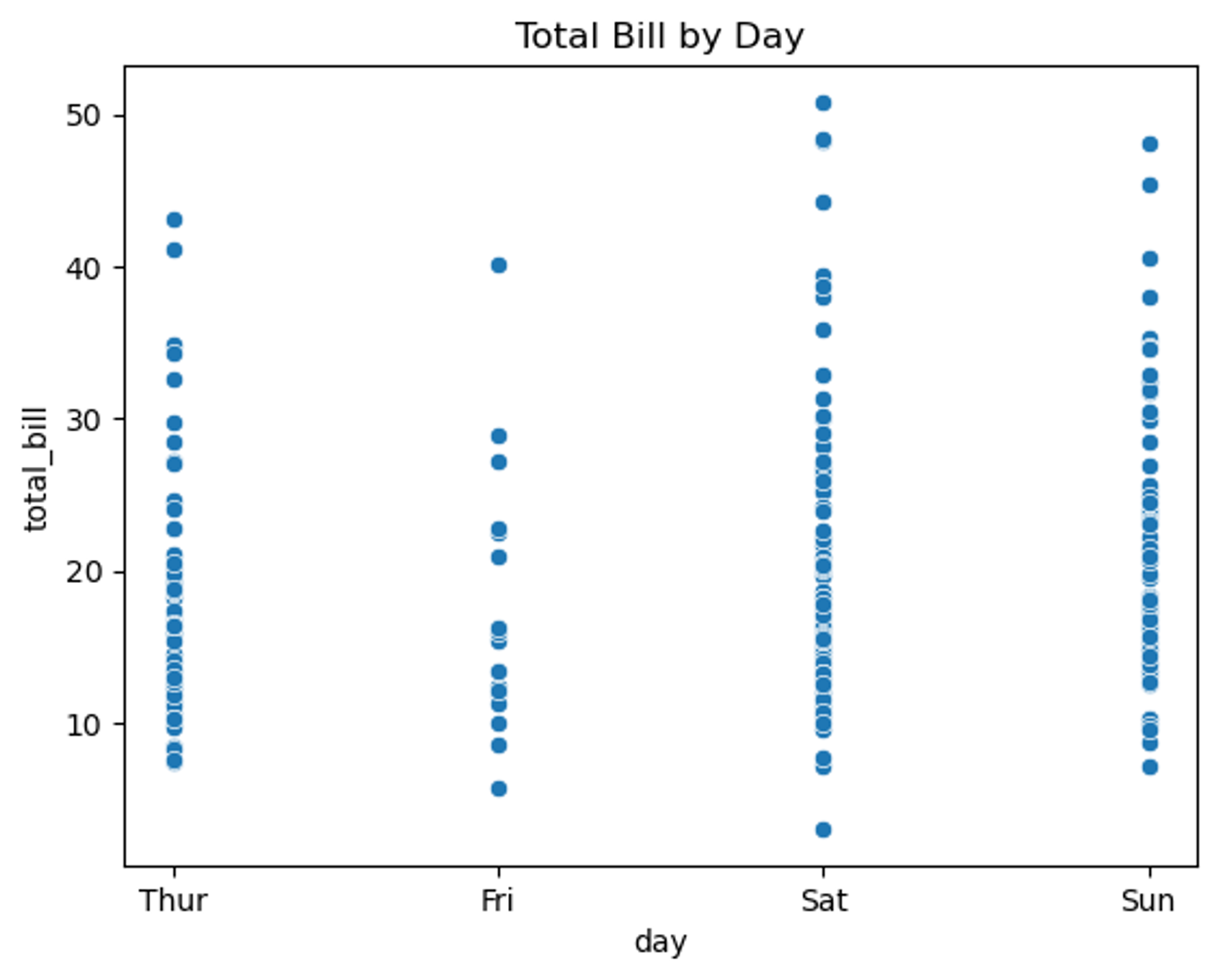
(2) Line Plot
① Line Plot
- 각 데이터 포인트는 그래프 상의 선으로 표시됨
- x축에 시간, y축에 다른 변수를 매핑 → 선을 이어 추세 파악
② 주요 특징
- 시계열 데이터 표현 : 시간의 흐름에 따른 데이터의 변화를 직관적으로 표현
- 전체적인 데이터의 변화∙추세 패턴 파악 : 데이터의 상승∙하락∙안정 등의 추세 확인
- 여러 데이터 셋 간의 비교 : 다양한 조건∙그룹에 대한 데이터의 변화를 동시에 비교
③ 한계
- 대량의 데이터 : 너무 많은 데이터 포인트를 포함하는 데이터 셋에선, 선 그래프가 지나치게 복잡해짐
- 연속성 가정 : 데이터 포인트 사이에 연속성이 있따고 가정. 범주형 데이터 같은 일부 유형에서는 부적절
- 과잉 해석 : 선 그래프의 연속적인 선은 데이터에 없는 패턴이나 추세를 제안할 수 있음. 이 때 과잉 해석의 위험이 존재
- 누락된 데이터의 처리 : 데이터가 누락되었을 때 선그래프가 어떻게 그려지는지에 대한 문제
④ 기본 사용법
sns.lineplot(data, x='x축이 될 변수', y='y축이 될 변수')
⑤ 예시
# 년도별 승객 수 변화
# 예제 데이터 생성
df = sns.load_dataset("flights")
# 기본 라인 플롯
sns.lineplot(data=df, x="year", y="passengers")
plt.title("Basic Line Plot")
plt.show()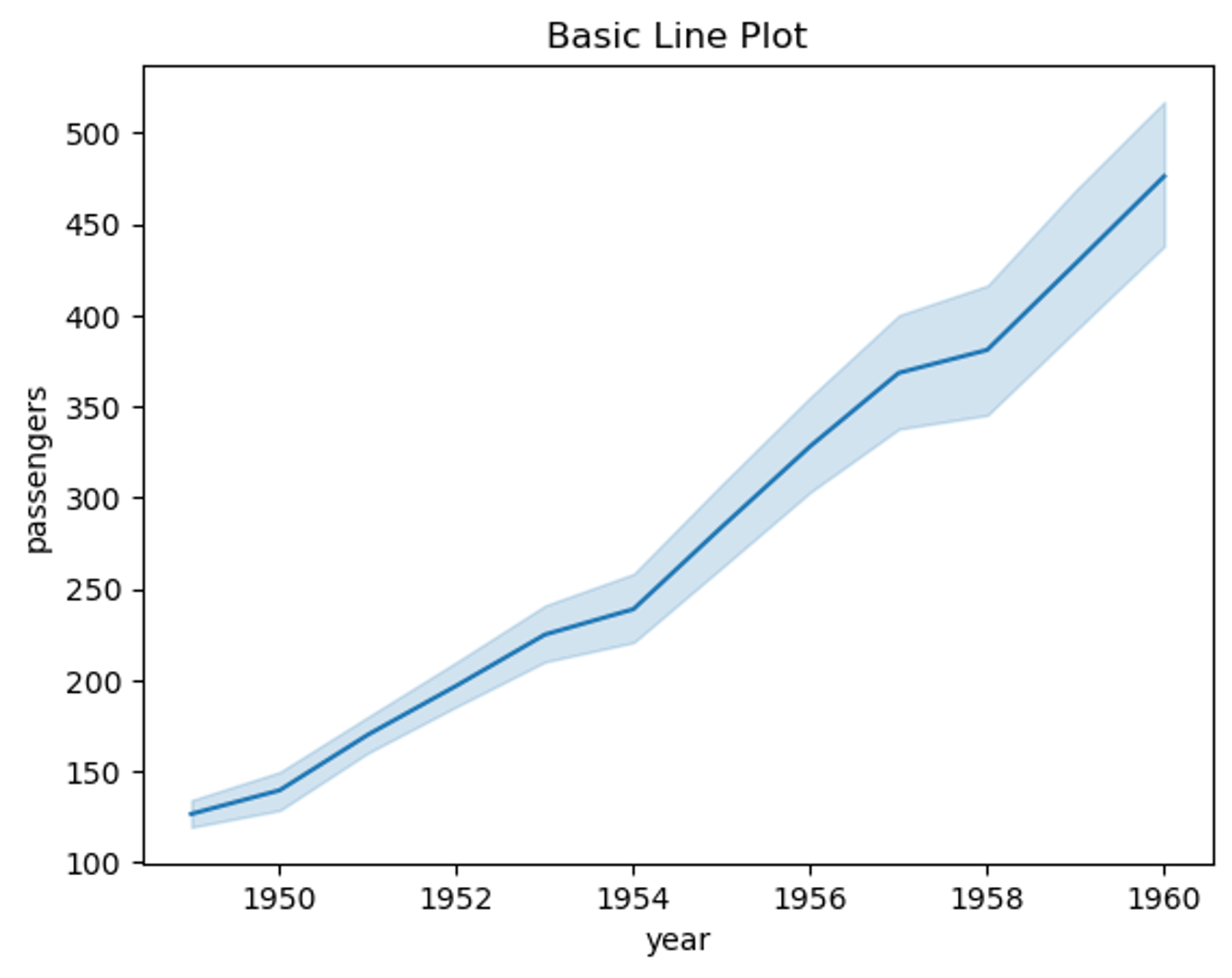
- 하늘색 면적 : 95% 신뢰구간(Confidence Interval)
* 신뢰구간 : 데이터의 불확실성 ∙ 변동성을 시각화. 95% 신뢰구간은 평균값 주위의 범위에서 실제값이 있을 확률이 95%라는 것. 하늘색 면적이 넓을수록 해당 구간에서의 데이터 변동성이 크다는 의미(좁을수록 데이터가 더 일관됨)
- 파란색 선 : 각 연도에 대한 승객 수의 평균값을 연결
(3) 다중 시각화
① FacetGrid
- 개념
- FacetGrid: seaborn 라이브러리에서 제공하는 다중 그래프 시각화 도구
- 데이터의 특정 조건에 따라 여러 플롯을 한 번에 생성할 수 있음
- 변수들 간의 관계를 다양한 조건에 따라 시각적으로 비교할 수 있음
② FacetGrid 주요 매개변수
- row, col: 플롯을 행과 열로 나누는 기준 변수
- hue: 범주에 따라 색상을 다르게 지정
- height: 각 서브플롯의 높이를 지정
- aspect: 서브플롯의 가로/세로 비율 조정
- margin_titles: 서브플롯의 제목을 간략히 표시
③ FacetGrid 사용 예시
- titanic 데이터: 성별(sex)과 객실 등급(class)에 따라 생존자 수의 분포를 확인
[tip]
- row="sex": 행 단위로 sex 변수를 기준으로 구분
- col="class": 열 단위로 class 변수를 기준으로 구분
- g.map(sns.histplot, "age"): 각 서브플롯에 대해 age 변수에 대한 히스토그램을 그림
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 로드
titanic = sns.load_dataset("titanic")
# FacetGrid 생성
g = sns.FacetGrid(titanic, row="sex", col="class")
g.map(sns.histplot, "age")
plt.show()
- hue 파라미터를 추가하여 성별, 객실 등급, 생존 여부에 따라 그래프를 세분화
[tip]
- hue="survived": 생존 여부(survived)에 따라 색상 구분
- margin_titles=True: 각 서브플롯의 제목을 간략하게 표시
- g.map(sns.scatterplot, "age", "fare", alpha=0.7): 각 서브플롯에 대해 age와 fare 변수를 이용한 산점도 그래프 그림
# FacetGrid 생성
g = sns.FacetGrid(titanic, row="sex", col="class", hue="survived", margin_titles=True)
g.map(sns.scatterplot, "age", "fare", alpha=0.7)
g.add_legend()
plt.show()
- FacetGrid와 kdeplot 결합: 분포의 커널 밀도 추정 그래프 그리기. tips 데이터를 사용하여 흡연 여부와 성별에 따른 팁 비율(tip/total_bill)의 분포를 시각화
[tip]
- g.map(sns.kdeplot, "tip_pct", fill=True): tip_pct 변수의 분포를 밀도 그래프로 시각화
- fill=True: 그래프를 채워 더욱 명확히 표현
# 데이터 로드
tips = sns.load_dataset("tips")
tips["tip_pct"] = tips["tip"] / tips["total_bill"] * 100
# FacetGrid 생성
g = sns.FacetGrid(tips, row="sex", col="smoker", margin_titles=True)
g.map(sns.kdeplot, "tip_pct", fill=True)
plt.show()
- FacetGrid와 boxplot 결합: 박스플롯을 통해 다양한 조건에서 변수의 분포와 중위수 등을 시각화
[tip]
- row="sex", col="day": 성별(sex)과 요일(day)별로 분리된 박스플롯 생성
- g.map(sns.boxplot, "smoker", "tip"): 흡연 여부(smoker)와 팁(tip) 변수 간의 분포를 박스플롯으로 나타냄
# FacetGrid 생성
g = sns.FacetGrid(tips, row="sex", col="day", margin_titles=True)
g.map(sns.boxplot, "smoker", "tip")
plt.show()📙 내일 일정
- 데이터 시각화

'TIL _Today I Learned > 2024.07' 카테고리의 다른 글
| [DAY 11] Plotly, Folium (2) | 2024.07.25 |
|---|---|
| [DAY 10] Data Visualization (1) | 2024.07.24 |
| [DAY 8] Data Manipulation, Data Preprocessing (0) | 2024.07.22 |
| [DAY 7] Data Manipulation (0) | 2024.07.19 |
| [DAY 6] Python Crawling (0) | 2024.07.18 |



