[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.12.23
📕 프로젝트 작업 내역
- Labeling Pipeline 자동화
📗 수행 결과
1. Labeling Pipeline 자동화
1) 라벨링 자동화 파이프라인
사용자 문제 업로드 (Django API) → S3 업로드 → Lambda 함수 실행 (S3 이벤트 트리거) → EC2 내 라벨링 파이프라인 실행 (YOLO > OCR > LLM) → 라벨링 결과 저장 (MongoDB) → 사용자 응답 (Django API)
2) Django → S3 업로드
S3 버킷에 업로드된 파일 유형을 다음 두 가지로 예상
(i) 텍스트 업로드 (Django 에서 .txt 로 변환 후 업로드)
- big9-project-02-question-bucket/text
(ii) 이미지 파일 업로드 (.png or .jpeg)
- big9-project-02-question-bucket/image
3) S3 업로드 → Lambda 함수 실행 (S3 이벤트 트리거)
(1) Lambda 함수 생성
(i) 텍스트 파일 업로드
- lambda 함수명: start_llm
(ii) 이미지 파일 업로드
- lambda 함수명: start_yolo_to_ocr
(2) S3 이벤트 알림 생성
(i) 텍스트 파일 업로드
- S3 버킷명: big9-project-02-question-bucket
- 폴더명: image

(ii) 이미지 파일 업로드
- S3 버킷명: big9-project-02-question-bucket
- 폴더명: text
(3) S3 업로드 → Lambda 함수 트리거 테스트
(i) 텍스트 파일 업로드
- S3에 텍스트 파일(text/.txt) 업로드
- Lambda 콘솔 → 모니터링 → CloudWatch → 로그 스트림 → 로그 이벤트 확인
(ii) 이미지 파일 업로드
- S3에 이미지 파일(image/.png) 업로드
- Lambda 콘솔 → 모니터링 → CloudWatch → 로그 스트림 → 로그 이벤트 확인
4) EC2 내 라벨링 폴더 생성
(1) YOLO/OCR 실행 스크립트 생성
- 폴더 경로: /home/ubuntu/labeling
- 파일명: yolo_to_ocr.py
import boto3
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from ultralytics import YOLO
import json
from PIL import Image
import uuid
# S3 설정
s3_client = boto3.client('s3')
MODEL_BUCKET_NAME = "big9-project-02-model-bucket"
YOLO_MODEL_PATH = "yolov8_test.pt"
OCR_MODEL_PATH = "trocr_test.pt"
IMAGE_BUCKET_NAME = "big9-project-02-question-bucket/image"
LOCAL_IMAGE_PATH = "/tmp/temp_image.jpg"
OUTPUT_JSON_PATH = "/tmp/result.json"
# 1. YOLO 모델 로드
def load_yolo_model():
local_yolo_path = "/tmp/yolo_model.pt"
s3_client.download_file(MODEL_BUCKET_NAME, YOLO_MODEL_PATH, local_yolo_path)
print(f"YOLO model downloaded to {local_yolo_path}")
model = YOLO(local_yolo_path)
return model
# 2. Fine-tuned TrOCR 모델 로드
def load_finetuned_trocr_model():
local_trocr_path = "/tmp/ocr_model.pt"
s3_client.download_file(MODEL_BUCKET_NAME, OCR_MODEL_PATH, local_trocr_path)
print(f"Fine-tuned OCR model downloaded to {local_trocr_path}")
processor = TrOCRProcessor.from_pretrained(local_trocr_path)
model = VisionEncoderDecoderModel.from_pretrained(local_trocr_path)
return processor, model
# 3. S3에서 이미지 다운로드
def download_image_from_s3(bucket_name, key, local_path):
s3_client.download_file(bucket_name, key, local_path)
print(f"Image downloaded from S3: {key} to {local_path}")
return local_path
# 4. YOLO로 바운딩 박스 추출
def extract_bboxes(yolo_model, image_path):
# YOLO 모델로 바운딩 박스 추출
results = yolo_model(image_path) # YOLO는 이미 640x640으로 리사이즈
bboxes = []
for result in results[0].boxes:
if int(result.cls.item()) == 0: # 클래스가 0인 경우만 처리
bboxes.append((
0, # class_id
result.xywh[0][0].item(), # x_center (0~1)
result.xywh[0][1].item(), # y_center (0~1)
result.xywh[0][2].item(), # width (0~1)
result.xywh[0][3].item() # height (0~1)
))
return bboxes
# 5. TrOCR로 텍스트 추출
def extract_text_from_bboxes(processor, model, image_path, bboxes):
# TrOCR 모델로 바운딩 박스를 이용해 텍스트 추출
image = Image.open(image_path).resize((384, 384)) # TrOCR 입력 크기로 리사이즈
question_text = []
for bbox in bboxes:
_, x_center, y_center, width, height = bbox
# 상대 좌표를 TrOCR 입력 크기에 맞게 변환
x_min = int((x_center - width / 2) * 384)
y_min = int((y_center - height / 2) * 384)
x_max = int((x_center + width / 2) * 384)
y_max = int((y_center + height / 2) * 384)
# 텍스트 추출
cropped_image = image.crop((x_min, y_min, x_max, y_max))
inputs = processor(images=cropped_image, return_tensors="pt").pixel_values
outputs = model.generate(inputs)
text = processor.batch_decode(outputs, skip_special_tokens=True)[0]
question_text.append(text.strip())
return question_text
# 6. JSON 저장
def save_to_json(image_id, bboxes, question_text, output_path):
data = {
"image_id": image_id,
"bboxes": bboxes, # YOLO에서 제공한 class_id 포함한 바운딩 박스
"question_text": " ".join(question_text) # 추출된 텍스트를 공백으로 연결
}
with open(output_path, "w", encoding="utf-8") as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=4)
print(f"Saved JSON to {output_path}")
return output_path
# 메인 함수
def main():
# 1. 고유 image_id 생성
image_id = str(uuid.uuid4()) # UUID로 고유 ID 생성
# 2. S3 이미지 경로 설정
image_key = f"{image_id}.jpg" # 이미지 파일 이름 생성
# 3. 모델 로드
yolo_model = load_yolo_model()
processor, trocr_model = load_finetuned_trocr_model()
# 4. S3에서 이미지 다운로드
local_image_path = download_image_from_s3(IMAGE_BUCKET_NAME, image_key, LOCAL_IMAGE_PATH)
# 5. YOLO로 바운딩 박스 추출
bboxes = extract_bboxes(yolo_model, local_image_path)
# 6. TrOCR로 텍스트 추출
if bboxes:
question_text_list = extract_text_from_bboxes(processor, trocr_model, local_image_path, bboxes)
# JSON 저장
save_to_json(image_id, bboxes, question_text_list, OUTPUT_JSON_PATH)
else:
print("No valid bounding boxes (class 0) found.")
# 실행
if __name__ == "__main__":
main()
(2) LLM 실행 스크립트 생성
- 폴더 경로: /home/ubuntu/labeling/LLM
- 파일명
- .env
- json_utils.py
- openai_utils.py
- problem_processor.py
- s3_utils.py
- main_text.py
# main_text.py: MongoDB와 연결 테스트 용
import os
from dotenv import load_dotenv
from pymongo import MongoClient
# .env 파일 로드
load_dotenv()
# 환경 변수에서 MongoDB 정보 가져오기
mongo_user = os.getenv("MONGO_USER")
mongo_password = os.getenv("MONGO_PASSWORD")
mongo_host = os.getenv("MONGO_HOST")
mongo_port = os.getenv("MONGO_PORT")
mongo_db = os.getenv("MONGO_DB")
collection_name = os.getenv("MONGO_COLLECTION_NAME")
# MongoDB URI 구성
mongo_uri = f"mongodb://{mongo_user}:{mongo_password}@{mongo_host}:{mongo_port}/?authSource=admin"
# MongoDB 클라이언트 연결
mongo_client = MongoClient(mongo_uri)
db = mongo_client[mongo_db]
collection = db[collection_name]
# MongoDB 연결 테스트
try:
mongo_client.admin.command("ping")
print(f"[INFO] Connected to MongoDB Database: {mongo_db}, Collection: {collection_name}")
except Exception as e:
print(f"[ERROR] MongoDB connection failed: {e}")
exit()
# MongoDB에 데이터 삽입 테스트
try:
test_data = {"key": "value", "status": "test"}
result = collection.insert_one(test_data)
print(f"[INFO] Test data inserted with ID: {result.inserted_id}")
except Exception as e:
print(f"[ERROR] Failed to insert test data: {e}")
finally:
mongo_client.close()
5) S3 - Lambda 함수 - EC2 연결
(1) Lambda 에서 SSM으로 EC2 접속 및 스크립트 실행
# 기존에 EC2 에 SSM Agent 설치한 상태
# SSM Agent 활성화 및 시작
sudo systemctl enable snap.amazon-ssm-agent.amazon-ssm-agent.service
sudo systemctl start snap.amazon-ssm-agent.amazon-ssm-agent.service
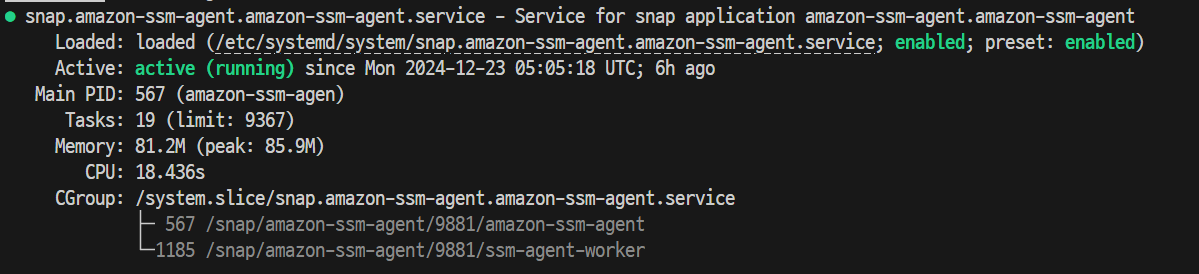
# SSM Agent 상태 확인
sudo systemctl status snap.amazon-ssm-agent.amazon-ssm-agent.service- SSM Agent 상태: 실행중
- SSM - EC2 연결 확인
# SSM-EC2 연결 확인
aws ssm describe-instance-information
"""
{
"InstanceInformationList": [
{
"InstanceId": "i-xxx",
"PingStatus": "Online",
"LastPingDateTime": "2024-12-23T11:33:14.897000+00:00",
"AgentVersion": "3.3.987.0",
"IsLatestVersion": false,
"PlatformType": "Linux",
"PlatformName": "Ubuntu",
"PlatformVersion": "24.04",
"ResourceType": "EC2Instance",
"IPAddress": "xxx",
"ComputerName": "ip-xxx",
"SourceId": "i-xxx",
"SourceType": "AWS::EC2::Instance"
},
...
]
}
"""
(2) Lambda 함수에서 SSM API 호출
- EC2에 존재하는 SSM 문서 목록 확인 (AWS-RunShellScript)
aws ssm list-documents --filters Key=Name,Values=AWS-RunShellScript
"""
{
"DocumentIdentifiers": [
{
"Name": "AWS-RunShellScript",
"CreatedDate": "2017-08-31T00:01:22.641000+00:00",
"Owner": "Amazon",
"PlatformTypes": [
"Linux",
"MacOS"
],
"DocumentVersion": "1",
"DocumentType": "Command",
"SchemaVersion": "1.2",
"DocumentFormat": "JSON",
"Tags": []
}
]
}
"""- Lambda 함수에서 SSM 호출 테스트 코드 작성
import boto3
import time
def lambda_handler(event, context):
ssm = boto3.client('ssm', region_name='ap-northeast-2')
instance_id = 'i-xxx' # 대상 EC2 인스턴스 ID
try:
print("Starting SSM send-command...")
response = ssm.send_command(
InstanceIds=[instance_id],
DocumentName='AWS-RunShellScript', # 실행할 SSM 문서
Parameters={
'commands': ['echo "Hello from Lambda!"']
}
)
# Command ID 반환
command_id = response['Command']['CommandId']
print(f"Command ID: {command_id}")
# 명령 상태 확인 (폴링)
timeout = 60 # 최대 60초 대기
elapsed_time = 0
while elapsed_time < timeout:
time.sleep(3) # 3초마다 확인
elapsed_time += 3
result = ssm.get_command_invocation(
CommandId=command_id,
InstanceId=instance_id
)
status = result['Status']
print(f"Command Status: {status}")
if status in ['Success', 'Failed', 'Cancelled', 'TimedOut']:
print("Command completed.")
print(f"Output: {result['StandardOutputContent']}")
return {
'statusCode': 200,
'body': f"Command Output: {result['StandardOutputContent']}"
}
print("Command timed out.")
return {
'statusCode': 500,
'body': "Command did not complete in time."
}
except Exception as e:
print(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': f"Error: {str(e)}"
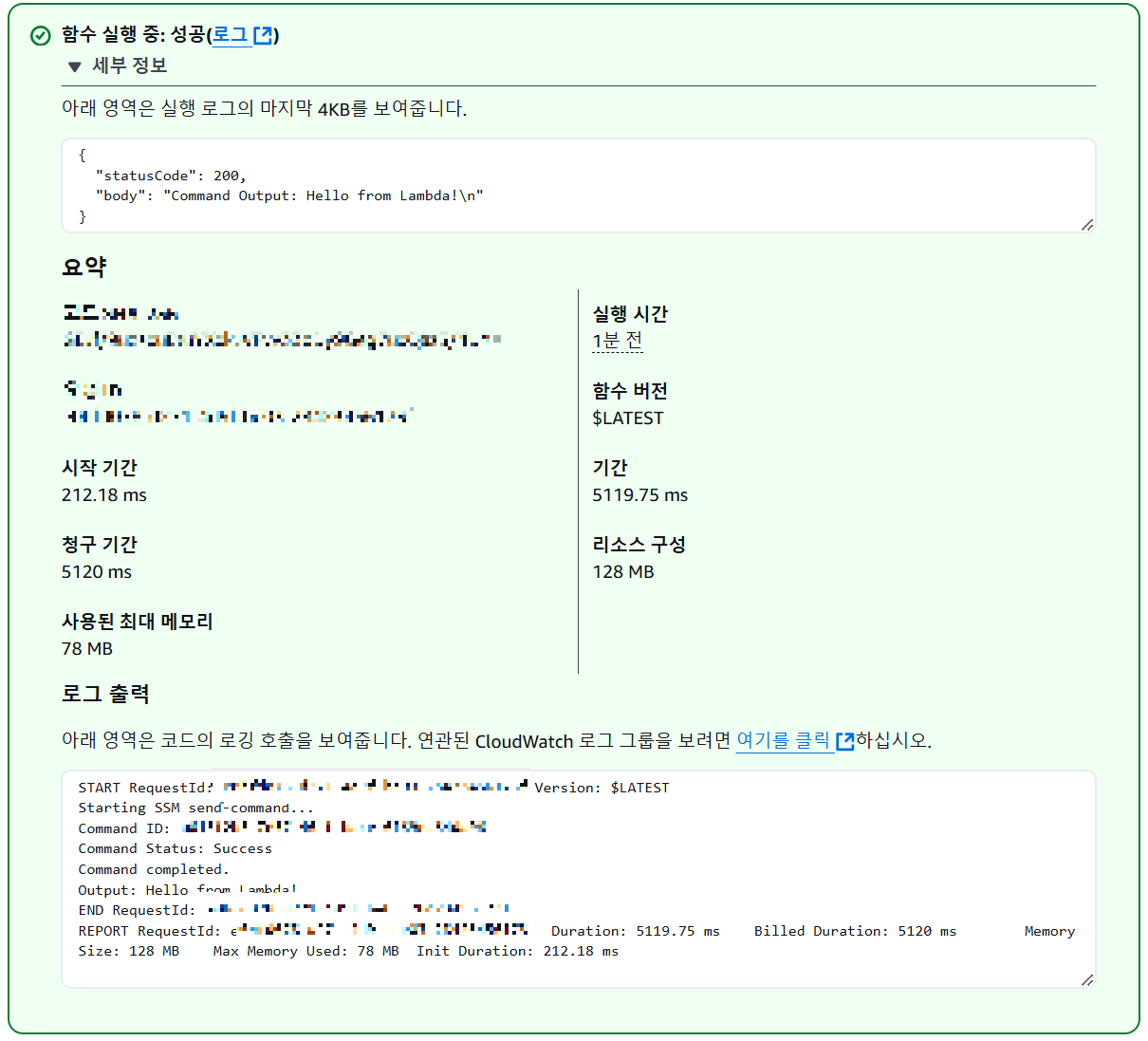
}- 비어있는 json 파일 {} 로 테스트 (구성>제한 시간 2분으로 늘림)
- 두 Lambda 함수에서 Lambda → SSM → EC2 연결 성공!
(3) S3 이벤트 트리거 → Lambda → SSM API → EC2 → 스크립트 실행 테스트
- 목표
- S3 이벤트 → Lambda 호출
- Lambda → SSM API 호출 → EC2 인스턴스에 명령 전달
- EC2 내 파이썬 스크립트 실행 시도 확인
① Lambda 함수 코드 변경
import boto3
def lambda_handler(event, context):
ssm = boto3.client('ssm', region_name='ap-northeast-2')
try:
print("Sending SSM command to EC2...")
response = ssm.send_command(
InstanceIds=['i-xxx'], # EC2 인스턴스 ID
DocumentName='AWS-RunShellScript',
Parameters={
'commands': [
"eval \"$(/home/ubuntu/miniconda3/bin/conda shell.bash hook)\" && conda activate label_pl", # 가상환경 실행
"python3 /home/ubuntu/labeling/LLM/main_text.py"
#"python3 /home/ubuntu/labeling/yolo_to_ocr.py"
]
}
)
# Command ID 반환
command_id = response['Command']['CommandId']
print(f"Command ID: {command_id}")
return {
'statusCode': 200,
'body': f"SSM Command successfully sent. Command ID: {command_id}"
}
except Exception as e:
print(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': f"Error: {str(e)}"
}
② S3 버킷(big9-project-02-question-bucket)에 테스트 파일 업로드
(i) 텍스트 파일 업로드
- 폴더 경로: text/
- 테스트 파일: test.txt
(ii) 이미지 파일 업로드
- 폴더 경로: image/
- 테스트 파일: test.png
③-1 CloudWatch 결과 확인
(i) 텍스트 파일 업로드
- Lambda > CloudWatch 로그 확인
- SSM 명령이 성공적으로 EC2에 전송됨
- Command ID 생성
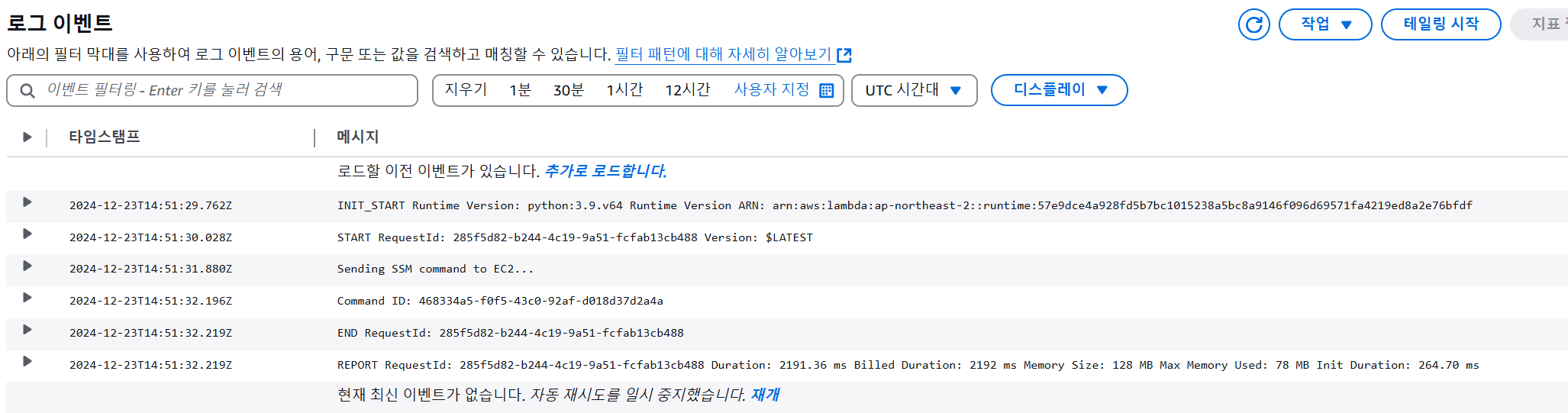
(ii) 이미지 파일 업로드
- Lambda > CloudWatch 로그 확인
- SSM 명령이 성공적으로 EC2에 전송됨
- Command ID 생성
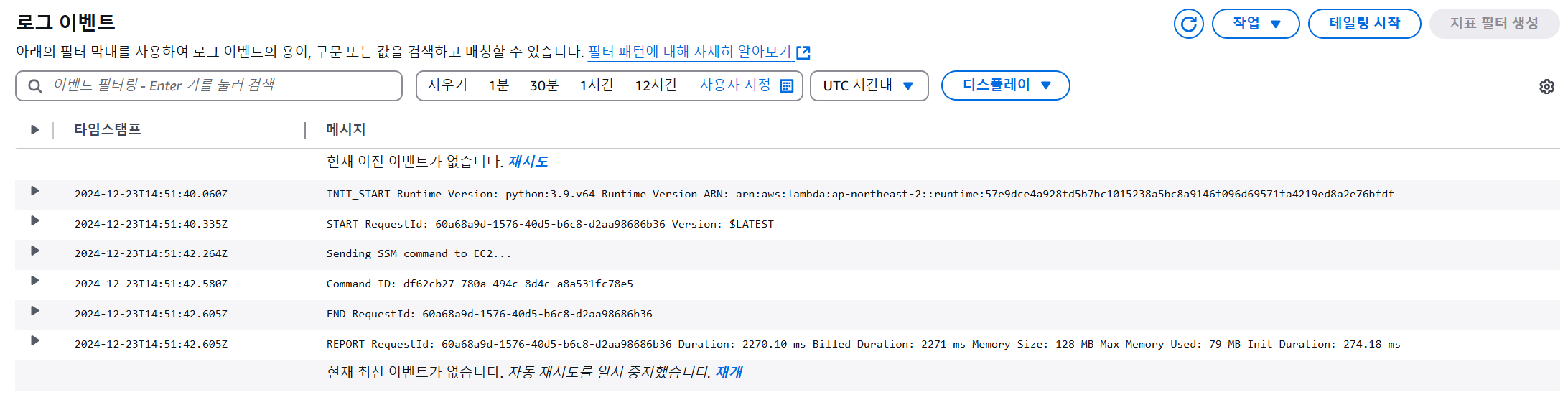
③-2 SSM Agent 결과 확인
(i) 텍스트 파일 업로드
- EC2 > SSM Agent 로그 확인
- Command ID 입력
- S3 에 txt 파일 업로드 → Lambda → SSM → EC2 → main.py → MongoDB 에 테스트 데이터 적재 성공!
aws ssm get-command-invocation \
--command-id "<COMMAND_ID>" \
--instance-id "<INSTANCE_ID>" \
--region "ap-northeast-2"
"""
{
"CommandId": "<COMMAND_ID>",
"InstanceId": "<INSTANCE_ID>",
"Comment": "",
"DocumentName": "AWS-RunShellScript",
"DocumentVersion": "$DEFAULT",
"PluginName": "aws:runShellScript",
"ResponseCode": 0,
"ExecutionStartDateTime": "2024-12-23T14:51:32.446Z",
"ExecutionElapsedTime": "PT2.502S",
"ExecutionEndDateTime": "2024-12-23T14:51:34.446Z",
"Status": "Success", # 성공!
"StatusDetails": "Success",
"StandardOutputContent": "[INFO] Connected to MongoDB Database: labelresults, Collection: results\n[INFO] Test data inserted with ID: 676978f65c732ce6b5fa5773\n",
"StandardOutputUrl": "",
"StandardErrorContent": "",
"StandardErrorUrl": "",
"CloudWatchOutputConfig": {
"CloudWatchLogGroupName": "",
"CloudWatchOutputEnabled": false
}
}
"""
(ii) 이미지 파일 업로드
- Lambda > CloudWatch 로그 확인
- Command ID 입력
- 실패! Error 내용: ModuleNotFoundError: No module named 'transformers'
aws ssm get-command-invocation \
--command-id "<COMMAND_ID>" \
--instance-id "<INSTANCE_ID>" \
--region "ap-northeast-2"
"""
{
"CommandId": "<COMMAND_ID>",
"InstanceId": "<INSTANCE_ID>",
"Comment": "",
"DocumentName": "AWS-RunShellScript",
"DocumentVersion": "$DEFAULT",
"PluginName": "aws:runShellScript",
"ResponseCode": 1,
"ExecutionStartDateTime": "2024-12-23T14:51:42.837Z",
"ExecutionElapsedTime": "PT2.087S",
"ExecutionEndDateTime": "2024-12-23T14:51:44.837Z",
"Status": "Failed", # 실패!
"StatusDetails": "Failed",
"StandardOutputContent": "",
"StandardOutputUrl": "",
"StandardErrorContent": "Traceback (most recent call last):\n File \"/home/ubuntu/labeling/yolo_to_ocr.py\", line 2, in <module>\n from transformers import TrOCRProcessor, VisionEncoderDecoderModel\nModuleNotFoundError: No module named 'transformers'\nfailed to run commands: exit status 1",
"StandardErrorUrl": "",
"CloudWatchOutputConfig": {
"CloudWatchLogGroupName": "",
"CloudWatchOutputEnabled": false
}
}
"""
- EC2에서 스크립트 실행해가며, 필요한 추가 모듈 설치
# 스크립트 실행
python /home/ubuntu/labeling/yolo_to_ocr.py
# 추가 모듈 설치
pip install transformers
pip install ultralytics
sudo apt-get update
sudo apt-get install -y libgl1- Hugging Face에서 제공하는 trocr-small-korean 모델은 디렉토리 형식의 구조를 가짐 ( .pt X)
- 모델 S3 버킷에 OCR 디렉토리 저장
trocr_directory/
├── pytorch_model.bin # 모델 가중치 파일
├── config.json # 모델 설정 파일
├── generation_config.json # 생성 관련 설정 파일
├── preprocessor_config.json # 전처리기 설정 파일
├── tokenizer_config.json # 토크나이저 설정 파일
├── tokenizer.json # 토크나이저 정의 파일
├── special_tokens_map.json # 특별 토큰 매핑 파일
├── sentencepiece.bpe.model # SentencePiece 토크나이저 모델 파일- yolo_to_ocr.py 코드 수정: subprocess 라이브러리 사용하여 두 번째 파이썬 스크립트(main_image.py)가 자동 실행되게 함
import boto3
import subprocess
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from ultralytics import YOLO
from dotenv import load_dotenv
import os
import stat
import json
from PIL import Image
import numpy as np
# 환경 변수 로드
load_dotenv()
# S3 설정
s3_client = boto3.client('s3')
MODEL_BUCKET_NAME = os.getenv("MODEL_BUCKET_NAME")
YOLO_MODEL_PATH = os.getenv("YOLO_MODEL_PATH")
OCR_MODEL_PATH = os.getenv("OCR_MODEL_PATH")
IMAGE_BUCKET_NAME = os.getenv("IMAGE_BUCKET_NAME")
IMAGE_PREFIX = os.getenv("IMAGE_PREFIX") # 이미지 경로(prefix)
LOCAL_YOLO_PATH = "/tmp/temp_yolo.pt" # YOLO 모델 임시 저장 경로
LOCAL_OCR_PATH = "/tmp/temp_ocr/" # OCR 모델 임시 저장 경로
LOCAL_IMAGE_PATH = "/tmp/temp_image.png" # 이미지 임시 저장 경로
OUTPUT_JSON_PATH = "/tmp/result.json" # YOLO - OCR 결과 임시 저장 경로
# 1. YOLO 모델 로드
def load_yolo_model():
try:
if os.path.exists(LOCAL_YOLO_PATH):
# 파일 쓰기 권한 확인 및 추가
if not os.access(LOCAL_YOLO_PATH, os.W_OK):
print(f"[WARNING] No write permission for {LOCAL_YOLO_PATH}. Changing permissions.")
os.chmod(LOCAL_YOLO_PATH, stat.S_IWUSR | stat.S_IRUSR)
# 기존 파일 삭제
os.remove(LOCAL_YOLO_PATH)
print(f"[INFO] Existing file {LOCAL_YOLO_PATH} deleted.")
# S3에서 YOLO 모델 다운로드
s3_client.download_file(MODEL_BUCKET_NAME, YOLO_MODEL_PATH, LOCAL_YOLO_PATH)
print(f"[INFO] YOLO model downloaded to {LOCAL_YOLO_PATH}")
# YOLO 모델 로드
model = YOLO(LOCAL_YOLO_PATH)
return model
except Exception as e:
print(f"[ERROR] Failed to load YOLO model: {e}")
raise e
# 2. Fine-tuned TrOCR 모델 로드
def load_finetuned_trocr_model():
os.makedirs(LOCAL_OCR_PATH, exist_ok=True) # 디렉터리가 없으면 생성
# S3에서 필요한 파일 리스트 정의
trocr_files = [
"config.json",
"pytorch_model.bin",
"tokenizer.json",
"tokenizer_config.json",
"preprocessor_config.json",
"generation_config.json"
]
# 파일 개별 다운로드
for file_name in trocr_files:
s3_file_path = f"{OCR_MODEL_PATH}/{file_name}"
local_file_path = f"{LOCAL_OCR_PATH}/{file_name}"
# 파일이 이미 존재하는 경우 처리
if os.path.exists(local_file_path):
# 파일 권한 확인 및 수정
if not os.access(local_file_path, os.W_OK):
print(f"[WARNING] No write permission for {local_file_path}. Changing permissions.")
os.chmod(local_file_path, stat.S_IWUSR | stat.S_IRUSR)
# 기존 파일 삭제
try:
os.remove(local_file_path)
print(f"[INFO] Existing file {local_file_path} deleted.")
except Exception as e:
print(f"[ERROR] Failed to delete {local_file_path}: {e}")
raise e
# S3에서 파일 다운로드
try:
s3_client.download_file(MODEL_BUCKET_NAME, s3_file_path, local_file_path)
print(f"[INFO] Downloaded {file_name} to {local_file_path}")
except Exception as e:
print(f"[ERROR] Failed to download {file_name}: {e}")
raise e
# 모델과 프로세서 로드
try:
processor = TrOCRProcessor.from_pretrained(LOCAL_OCR_PATH)
model = VisionEncoderDecoderModel.from_pretrained(LOCAL_OCR_PATH)
print(f"[INFO] Fine-tuned TrOCR model loaded from {LOCAL_OCR_PATH}")
return processor, model
except Exception as e:
print(f"[ERROR] Failed to load TrOCR model: {e}")
raise e
# 3. S3에서 이미지 목록 가져오기
def list_images_in_s3(bucket_name, prefix):
try:
response = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
if "Contents" not in response:
raise ValueError("No files found in the specified bucket and prefix.")
files = [obj["Key"] for obj in response["Contents"] if obj["Key"].endswith((".png", ".jpg"))]
print(f"Found {len(files)} image files.")
return files
except Exception as e:
print(f"[ERROR] Failed to list images from S3: {e}")
raise e
# 4. S3에서 이미지 다운로드
def download_image_from_s3(bucket_name, key, local_path):
try:
# 로컬 경로에 디렉토리 생성 확인
os.makedirs(os.path.dirname(local_path), exist_ok=True)
if os.path.exists(local_path):
os.remove(local_path) # 기존 파일 삭제
s3_client.download_file(bucket_name, key, local_path)
print(f"Image downloaded from S3: {key} to {local_path}")
return local_path
except Exception as e:
print(f"[ERROR] Failed to download image from S3: {e}")
raise e
def extract_bboxes(yolo_model, image_path):
try:
# YOLO 모델 추론
results = yolo_model(image_path) # YOLO는 파일 경로 입력을 직접 지원
bboxes = []
for result in results[0].boxes:
if int(result.cls.item()) == 0: # 클래스가 0인 경우만 처리
bboxes.append([
0, # class_id
result.xywh[0][0].item(), # x_center
result.xywh[0][1].item(), # y_center
result.xywh[0][2].item(), # width
result.xywh[0][3].item() # height
])
# 바운딩 박스가 없는 경우 기본값 반환 (just 연결 테스트용!)
if not bboxes:
print("[WARNING] No bounding boxes found. Returning default bounding box.")
bboxes.append([0, 0, 0, 0, 0])
return bboxes
except Exception as e:
print(f"[ERROR] Failed to extract bounding boxes: {e}")
return [[0, 0, 0, 0, 0]] # 오류 발생 시 기본값 반환 (just 연결 테스트용!)
# 6. TrOCR로 텍스트 추출
def extract_text_from_bboxes(processor, model, image_path, bboxes):
try:
image = Image.open(image_path).resize((384, 384)) # TrOCR 입력 크기로 리사이즈
question_text = []
for bbox in bboxes:
_, x_center, y_center, width, height = bbox
x_min = max(0, int((x_center - width / 2) * 384))
y_min = max(0, int((y_center - height / 2) * 384))
x_max = min(384, int((x_center + width / 2) * 384))
y_max = min(384, int((y_center + height / 2) * 384))
if x_min >= x_max or y_min >= y_max:
print("[WARNING] Skipping invalid bounding box with zero or negative area.")
continue
cropped_image = image.crop((x_min, y_min, x_max, y_max))
inputs = processor(images=cropped_image, return_tensors="pt").pixel_values
outputs = model.generate(inputs)
text = processor.batch_decode(outputs, skip_special_tokens=True)[0]
question_text.append(text.strip())
# 텍스트가 없을 경우 기본 메시지 추가 (just 연결 테스트용!)
if not question_text:
question_text.append("테스트 메시지입니다")
return question_text
except Exception as e:
print(f"[ERROR] Failed to extract text from bounding boxes: {e}")
return ["테스트 메시지입니다"] # 오류 발생 시 기본값 반환 (just 연결 테스트용!)
# 7. JSON 저장
def save_to_json(image_id, bboxes, question_text, output_path):
try:
# 기존 JSON 파일 삭제
if os.path.exists(output_path):
os.remove(output_path)
print(f"[INFO] Existing JSON file deleted: {output_path}")
data = {
"image_id": image_id,
"bboxes": bboxes,
"question_text": " ".join(question_text)
}
with open(output_path, "w", encoding="utf-8") as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=4)
print(f"Saved JSON to {output_path}")
return output_path
except Exception as e:
print(f"[ERROR] Failed to save JSON: {e}")
raise e
# 메인 함수
def main():
# 모델 로드
yolo_model = load_yolo_model()
processor, trocr_model = load_finetuned_trocr_model()
# S3 이미지 경로 설정
image_files = list_images_in_s3(IMAGE_BUCKET_NAME, IMAGE_PREFIX)
for idx, image_key in enumerate(image_files, start=1):
# 고유 image_id 생성
image_id = f"image_{idx}"
# S3에서 이미지 다운로드
local_image_path = download_image_from_s3(IMAGE_BUCKET_NAME, image_key, LOCAL_IMAGE_PATH)
# YOLO로 바운딩 박스 추출
bboxes = extract_bboxes(yolo_model, local_image_path)
# TrOCR로 텍스트 추출
if bboxes:
question_text_list = extract_text_from_bboxes(processor, trocr_model, local_image_path, bboxes)
# JSON 저장
save_to_json(image_id, bboxes, question_text_list, OUTPUT_JSON_PATH)
else:
print(f"No valid bounding boxes found for image {image_key}.")
# 실행
if __name__ == "__main__":
main() # 현재 작업 실행
# 다음 작업(두 번째 파일 실행)
try:
print("[INFO] Triggering the second script (main_image.py)...")
subprocess.run(
["python", "main_image.py"], # LLM 폴더에서 main_image.py 실행
check=True,
cwd=os.path.join(os.path.dirname(__file__), "LLM") # LLM 디렉토리로 이동
)
except subprocess.CalledProcessError as e:
print(f"[ERROR] Failed to execute the second script: {e}")# 자주 발생한 Error
[ERROR] Failed to save JSON: [Errno 1] Operation not permitted: '/tmp/result.json'
PermissionError: [Errno 1] Operation not permitted: '/tmp/result.json'
# Error 분석
파일이 이미 존재하지만 현재 사용자가 해당 파일을 삭제하거나 수정할 권한이 없을 때 발생
# 해결
# 1) 임시 저장 폴더의 기존 파일 삭제
sudo rm -f /tmp/result.json
# 2) 임시 저장 폴더에 파일을 저장할 때, 기존 파일은 삭제하고 새로 저장되게 코드 수정
def save_to_json(image_id, bboxes, question_text, output_path):
try:
# 기존 JSON 파일 삭제
if os.path.exists(output_path):
os.remove(output_path) # <- 여기!!!!!!!!!!!!!!!!!!!
print(f"[INFO] Existing JSON file deleted: {output_path}")
data = {
"image_id": image_id,
"bboxes": bboxes,
"question_text": " ".join(question_text)
}
with open(output_path, "w", encoding="utf-8") as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=4)
print(f"Saved JSON to {output_path}")
return output_path
except Exception as e:
print(f"[ERROR] Failed to save JSON: {e}")
raise e- main_image.py
import os
import json
from dotenv import load_dotenv
from pymongo import MongoClient
# .env 파일 로드
load_dotenv()
# 환경 변수에서 MongoDB 정보 가져오기
mongo_user = os.getenv("MONGO_USER")
mongo_password = os.getenv("MONGO_PASSWORD")
mongo_host = os.getenv("MONGO_HOST")
mongo_port = os.getenv("MONGO_PORT")
mongo_db = os.getenv("MONGO_DB")
collection_name = os.getenv("MONGO_COLLECTION_NAME")
# MongoDB URI 구성
mongo_uri = f"mongodb://{mongo_user}:{mongo_password}@{mongo_host}:{mongo_port}/?authSource=admin"
# MongoDB 클라이언트 연결
mongo_client = MongoClient(mongo_uri)
db = mongo_client[mongo_db]
collection = db[collection_name]
# MongoDB 연결 테스트
try:
mongo_client.admin.command("ping")
print(f"[INFO] Connected to MongoDB Database: {mongo_db}, Collection: {collection_name}")
except Exception as e:
print(f"[ERROR] MongoDB connection failed: {e}")
exit()
# MongoDB에 데이터 삽입 테스트
try:
test_data = {"key": "value", "status": "test"}
result = collection.insert_one(test_data)
print(f"[INFO] Test data inserted with ID: {result.inserted_id}")
except Exception as e:
print(f"[ERROR] Failed to insert test data: {e}")
finally:
mongo_client.close()
# JSON 파일 경로 (첫 번째 스크립트에서 저장된 경로)
OUTPUT_JSON_PATH = "/tmp/result.json"
def perform_llm_task(question_text):
"""
LLM 작업 수행
"""
# LLM 수행 로직
print(f"[INFO] Performing LLM task with question_text: {question_text}")
# 예: GPT 모델 호출, API 호출 등
response = f"LLM response for: {question_text}"
return response
def main():
# JSON 파일 로드
if not os.path.exists(OUTPUT_JSON_PATH):
print(f"[ERROR] JSON file not found at {OUTPUT_JSON_PATH}")
return
try:
with open(OUTPUT_JSON_PATH, "r", encoding="utf-8") as f:
data = json.load(f)
print(f"[INFO] Loaded JSON data: {data}")
# question_text 추출
question_text = data.get("question_text", "")
if not question_text:
print("[WARNING] No question_text found in JSON file.")
return
# LLM 작업 수행
response = perform_llm_task(question_text)
print(f"[INFO] LLM task completed. Response: {response}")
except Exception as e:
print(f"[ERROR] Failed to process JSON file: {e}")
# 실행
if __name__ == "__main__":
main()
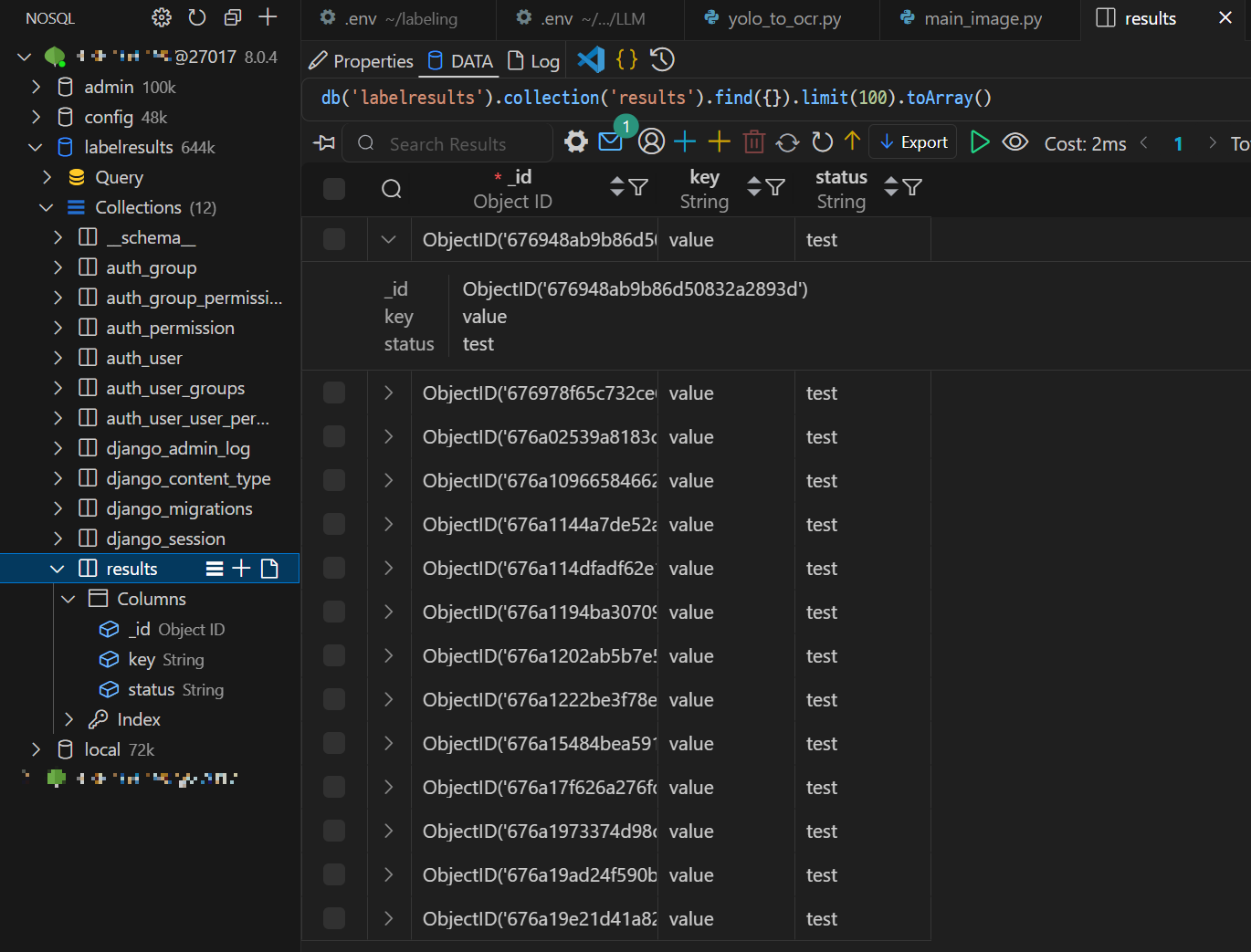
6) 라벨링 결과 MongoDB 적재 확인
- S3 업로드 → Lambda 함수 실행 → EC2 내 라벨링 파이프라인 실행 → 라벨링 결과 MongoDB 저장 성공!
- Binary JSON 형식으로 저장
{
"_id": "ObjectId(...)",
"key": "value",
"status": "test"
}
📙 내일 일정
- LLM 출력 내용 수정
- 학습된 모델로 갈아 끼우기
- 라벨링 파이프라인 내 CI/CD
- 업로드 시간 줄이기 5s/20s ->

'TIL _Today I Learned > 2024.12' 카테고리의 다른 글
| [DAY 111] 최종 프로젝트_ Lambda (1) | 2024.12.26 |
|---|---|
| [DAY 110] 최종 프로젝트_ 라벨링 자동화 파이프라인 개선 (0) | 2024.12.24 |
| [DAY 108] 최종 프로젝트_ 모델 추가 학습 (0) | 2024.12.20 |
| [DAY 107] 최종 프로젝트_ OCR 모델 Fine Tuning (0) | 2024.12.19 |
| [DAY 106] 최종 프로젝트_ Labeling Pipeline (2) | 2024.12.18 |



