📕 프로젝트 작업 내역
- 라벨링 파이프라인 자동화 구현
📗 수행 결과
1. 라벨링 파이프라인 자동화 구현
1) 자동화 구현 목표
S3에 교육과정 로드맵 업로드(JSON) → Lambda 실행 → EC2 내 형식 변환 스크립트(json_to_neo4j.py) 실행 → JSON 데이터를 Neo4j 형식으로 변환 → Neo4j 적재
2) AWS 아키텍처 구성 흐름
① S3 이벤트 트리거 설정
- JSON 파일이 S3에 업로드되면 Lambda 함수 실행
- Lambda 함수에서 해당 JSON 파일 정보를 받을 준비
② Lambda에서 EC2로 명령 실행
- Lambda가 EC2에 SSH로 접속하거나 AWS Systems Manager (SSM)를 통해 EC2에서 명령을 실행
- 이 명령은 EC2 내 형식 변환 스크립트(json_to_neo4j.py)가 실행되도록 트리거
③ EC2에서 작업 수행
- EC2 내부에 형식 변환 스크립트 배치
- EC2 내 Docker 컨테이너(neo4j-container) 배치
- 형식 변환 스크립트는 JSON 데이터를 Neo4j로 변환하고 데이터를 적재
3) 단계별 상세 구현
(1) S3 업로드 → Lambda 함수 트리거
① Lambda 함수 생성
- 함수명: start_json_to_neo4j
- EC2와 VPC, 서브넷, 보안그룹을 일치시킴
* 보안 그룹: 인바운드 규칙에 Neo4j 기본 포트(7474, 7687) 추가

② S3 생성
- 버킷명: big9-project-02-roadmap-bucket
- 폴더명: roadmap_2022
③ S3 이벤트 알림 설정
- 이벤트명: event_for_start_json_to_neo4j



④ S3 업로드 → Lambda 함수 트리거 테스트
- S3에 JSON 파일 업로드
- Lambda 콘솔 → 모니터링 → CloudWatch → 로그 스트림 → 로그 이벤트 확인
- INIT_START
- Lambda 함수가 처음 초기화될 때 발생하는 로그
- 이는 Lambda가 호출되었고, 실행 환경이 준비되었음을 나타냄
- START RequestId
- Lambda 함수 실행이 시작되었음을 나타냄
- 여기서 RequestId는 Lambda 실행의 고유 ID로, 동일한 요청에 대한 모든 로그를 추적할 수 있음
- END RequestId
- Lambda 함수 실행이 끝났음을 나타냄
- Lambda 코드가 성공적으로 실행되었거나 오류 없이 종료되었다는 것을 의미
- REPORT RequestId
- 실행 시간, 메모리 사용량 등의 리소스 보고가 포함된 로그
- INIT_START


(2) EC2 에 Neo4j 컨테이너 생성
[tip] 왜 EC2 접속 후, 터미널에 프라이빗 IP가 표시될까?
- AWS의 내부 네트워크(VPC)에서 통신할 때는 프라이빗 IP를 사용. 이는 외부 네트워크(인터넷)와는 독립적으로 동작
- SSH로 접속할 때, 퍼블릭 IP를 통해 연결하더라도 실제 접속 후에는 AWS 네트워크 내부에서 프라이빗 IP가 기본적으로 표시됨
| 퍼블릭 IP | 프라이빗 IP | |
| 용도 | 외부에서 EC2에 접근 | VPC 내부 리소스 간 통신 |
| 할당 | 인터넷 게이트웨이를 통해 외부에 노출됨 | AWS 네트워크(VPC) 내에서만 유효 |
| 변경 여부 | 퍼블릭 IP는 재부팅 시 변경될 수 있음 | 프라이빗 IP는 고정(재부팅 시 유지) |
| 접속 경로 | 외부 클라이언트가 EC2에 연결할 때 사용 | EC2 간 내부 통신 및 AWS 서비스 접근 시 사용 |
① Docker 설치
# 패키지 설치 전 항상 실행; 패키지 관리 도구(apt)가 사용하는 패키지 목록을 업데이트
sudo apt update
# docker.io 패키지 설치 (-y: 사용자 응답을 자동으로 yes로 하여 설치 진행)
sudo apt install -y docker.io
# Docker 서비스 시작; Docker 데몬이 실행되어야 컨테이너를 실행할 수 있음
sudo systemctl start docker
# 현재 사용자를 Docker 그룹에 추가; Docker 그룹에 포함된 사용자는 sudo 없이 Docker 명령어를 실행할 수 있음
sudo usermod -aG docker ubuntu # ubuntu: 현재 로그인된 사용자 이름* 현재 사용자(ubuntu)를 Docker 그룹에 추가한 뒤, 세션 로그아웃 후 다시 로그인해야 변경 사항이 적용됨(or "newgrp docker" 명령어를 통해 변경 사항을 즉시 적용)
② 제대로 설치되었는지 확인
docker --version
"""
Docker version 26.1.3, build 26.1.3-0ubuntu1~24.04.1
"""
③ Neo4j Docker 이미지 Pull
# Neo4j 최신 이미지 가져오기
docker pull neo4j:latest
# 원하는 버전의 이미지 가져오기
# docker pull neo4j:4.4.12
# Neo4j를 컨테이너로 실행
docker run -d \
--name neo4j-container \
-p 7474:7474 -p 7687:7687 \ # 7474: HTTP 인터페이스 포트, 7687: Bolt 프로토콜 포트
-e NEO4J_AUTH=neo4j/test \ # 사용자명(neo4j)과 비밀번호(test) 설정
neo4j:latest
# 실행 중인 컨테이너 확인
docker ps
④ Neo4j 컨테이너 원격 연결 테스트
- 주소창에 http://<EC2 Public IP>:7474
- Neo4j Username, Password 입력
- 연결 성공
(3) EC2 내에 형식 변환 스크립트(json_to_neo4j.py) 생성
① json_to_neo4j.py 실행을 위한 conda 가상환경 생성
- 가상환경 이름: neo4j_env
② .env 파일 생성
# .env 파일 생성 및 내용 입력
nano /home/ubuntu/.env# env
NEO4J_URI=bolt://<EC2 Public IP>:7687
NEO4J_USERNAME=
NEO4J_PASSWORD=[tip] "http://<EC2 Public IP>:7474" 와 "bolt://<EC2 Public IP>:7687" 의 차이
| HTTP 프로토콜 | BOLT 프로토콜 | |
| 사용 목적 | Neo4j 웹 인터페이스(Neo4j Browser)에 접속 | Neo4j와 프로그래밍 언어 간 직접 데이터 통신 |
| 용도 | 웹 기반 UI를 통해 Cypher 쿼리 실행 및 탐색 | Python, Java 등 클라이언트에서 데이터 읽기/쓰기 |
| 기본 포트 | 7474 | 7687 |
| 프로토콜 유형 | HTTP (텍스트 기반 프로토콜) | Bolt (이진 프로토콜, 효율적 데이터 전송) |
| 접근 방법 | 브라우저 주소창에 입력: | Neo4j 드라이버에서 연결: |
| http://<EC2 Public IP>:7474 | GraphDatabase.driver("bolt://<EC2 Public IP>:7687", auth=("username", "password")) | |
| 장점 | 사용자가 쉽게 UI를 통해 Neo4j와 상호작용 가능 | 클라이언트와 Neo4j 간 고성능 데이터 처리 가능 |
| 주요 사용 사례 | 브라우저 기반 쿼리 실행 및 데이터 탐색 | 애플리케이션에서 Neo4j 데이터를 조작하거나 조회 |
③ 형식 변환 스크립트(json_to_neo4j.py) 생성
* 파일 위치 찾기 명령어: ls ~/json_to_neo4j.py
# json_to_neo4j.py 파일 생성 및 내용 입력
/home/ubuntu/json_to_neo4j.py# json_to_neo4j.py
# Neo4j와 연결 테스트 용
import os
from neo4j import GraphDatabase
from dotenv import load_dotenv
# 환경 변수 로드
load_dotenv("/home/ubuntu/.env")
uri = os.getenv("NEO4J_URI")
username = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
# Neo4j 연결 테스트
driver = GraphDatabase.driver(uri, auth=(username, password))
session = driver.session()
# 테스트 쿼리 실행
result = session.run("RETURN 'Neo4j 연결 성공!' AS message")
for record in result:
print(record["message"])
session.close()
driver.close()
④ 형식 변환 스크립트(json_to_neo4j.py) 실행
- 스크립트가 위치한 경로에서 실행
python json_to_neo4j.py
"""
Neo4j 연결 성공!
"""
(4) Lambda에서 SSM으로 EC2 접속 및 스크립트 실행
[tip] SSM or SSH로 EC2 접속
| SSM (AWS Systems Manager) | SSH (Secure Shell) | |
| 정의 | AWS에서 제공하는 관리 서비스로, 클라우드와 온프레미스 인프라를 중앙에서 관리할 수 있도록 설계된 도구 | 보안 프로토콜로, 원격 서버와 안전하게 통신하기 위해 사용 |
| 기능 | AWS EC2 인스턴스 및 기타 AWS 리소스에 명령을 실행하거나 설정을 관리하고, 문제를 해결할 수 있는 다양한 기능을 제공 | 주로 서버 관리 및 명령 실행을 위해 사용되며, 암호화된 연결을 통해 데이터를 안전하게 전송 |
| 설정 편의성 |
IAM 역할만 추가하면 간단히 설정 가능 | SSH 키 관리 필요, 보안 그룹에 SSH 포트 열어야 함 |
| 보안 | 안전한 AWS 내부 통신 | SSH 키 노출 시 보안 문제 발생 가능 *EC2 pem 키를 S3에 저장 후 Lambda에 URI 입력해야 함 |
| 확장성 | Lambda에서 여러 EC2를 쉽게 관리 가능 | 여러 키와 IP 관리 필요 |
| 작업 추적 |
명령 실행 내역을 AWS Console에서 확인 가능 | 별도의 로그 관리 필요 |
| 네트워크 의존성 |
VPC나 퍼블릭 IP 없이도 사용 가능 | 퍼블릭 IP와 포트 22 접근 필요 |
| 유료 여부 |
대부분 무료 (로그 저장 등 일부 기능 유료) | 무료 |
① EC2에 SSM Agent 설치
# Snap으로 SSM Agent 설치
sudo apt update
sudo snap install amazon-ssm-agent --classic
# SSM Agent 활성화 및 시작
sudo systemctl enable snap.amazon-ssm-agent.amazon-ssm-agent.service
sudo systemctl start snap.amazon-ssm-agent.amazon-ssm-agent.service
# SSM Agent 상태 확인
sudo systemctl status snap.amazon-ssm-agent.amazon-ssm-agent.service- SSM Agent 상태: 실행중

② SSM - EC2 연결 확인 (AWS CLI)
[문제 상황]
EC2 권한 부족으로 연결확인 불가!

[해결 과정]
- 권한 부여: EC2 에 연결된 Role에 ' AmazonSSMManagedInstanceCore' 권한 추가
- SSM Agent 재시작 및 SSM 상태 확인
# SSM 재시작
sudo systemctl restart snap.amazon-ssm-agent.amazon-ssm-agent.service
# SSM 상태 확인
sudo systemctl status snap.amazon-ssm-agent.amazon-ssm-agent.service- SSM - EC2 연결 확인 연결 성공!
aws ssm describe-instance-information
"""
{
"InstanceInformationList": [
{
"InstanceId": "xxx",
"PingStatus": "Online",
"LastPingDateTime": "2024-12-16T01:57:51.091000+00:00",
"AgentVersion": "3.3.987.0",
"IsLatestVersion": false,
"PlatformType": "Linux",
"PlatformName": "Ubuntu",
"PlatformVersion": "24.04",
"ResourceType": "EC2Instance",
"IPAddress": "xxx",
"ComputerName": "ip-xxx",
"SourceId": "xxx",
"SourceType": "AWS::EC2::Instance"
}
]
}
"""
③ Lambda함수에서 SSM API 호출
- EC2 에 존재하는 SSM 문서 목록 확인 (AWS-RunShellScript)
aws ssm list-documents --filters Key=Name,Values=AWS-RunShellScript
"""
{
"DocumentIdentifiers": [
{
"Name": "AWS-RunShellScript",
"CreatedDate": "2017-08-31T00:01:22.641000+00:00",
"Owner": "Amazon",
"PlatformTypes": [
"Linux",
"MacOS"
],
"DocumentVersion": "1",
"DocumentType": "Command",
"SchemaVersion": "1.2",
"DocumentFormat": "JSON",
"Tags": []
}
]
}
"""- Lambda 함수에 'AmazonSSMFullAccess' 권한 부여
- Lambda 함수에서 SSM 호출 테스트 코드 작성
# Lambda
import boto3
ssm = boto3.client('ssm', region_name='ap-northeast-2')
response = ssm.send_command(
InstanceIds=['i-xxxxxxxxxxxxxxxxx'], # 대상 EC2 인스턴스 ID
DocumentName='AWS-RunShellScript', # 실행할 SSM 문서
Parameters={
'commands': ['echo "Hello from Lambda!"'] # EC2에서 실행할 명령어
}
)
print("Command ID:", response['Command']['CommandId'])
[문제 상황]
Lambda 함수 테스트 실행시 계속 time out 됨

[해결 과정]
[시도 1]
- 문제 원인 파악: Lambda 제한 시간 부족
- 해결: Lambda 콘솔 > 구성 > 일반 구성 > 제한 시간 2분 으로 늘림
- 결과: 새로운 에러(에러 코드 500) 발생

[시도 2]
- 문제 원인 파악: Lambda 가 SSM 엔드포인트에 접근할 수 없음
[tip] SSM 엔드포인트
• SSM 엔드포인트: AWS SDK (boto3) 가 Lambda 함수가 실행되는 리전에 따라 자동으로 선택
• Lambda 함수의 리전이 'ap-northeast-2' → boto3는 SSM의 기본 엔드포인트로 'https://ssm.ap-northneast-2.amazonaws.com'을 사용
- 해결1: VPC 엔드포인트 생성




- 해결2: Lambda 함수 변경
import boto3
import time
def lambda_handler(event, context):
ssm = boto3.client('ssm', region_name='ap-northeast-2')
instance_id = 'i-xxx' # 대상 EC2 인스턴스 ID
try:
print("Starting SSM send-command...")
response = ssm.send_command(
InstanceIds=[instance_id],
DocumentName='AWS-RunShellScript', # 실행할 SSM 문서
Parameters={
'commands': ['echo "Hello from Lambda!"']
}
)
# Command ID 반환
command_id = response['Command']['CommandId']
print(f"Command ID: {command_id}")
# 명령 상태 확인 (폴링)
timeout = 60 # 최대 60초 대기
elapsed_time = 0
while elapsed_time < timeout:
time.sleep(3) # 3초마다 확인
elapsed_time += 3
result = ssm.get_command_invocation(
CommandId=command_id,
InstanceId=instance_id
)
status = result['Status']
print(f"Command Status: {status}")
if status in ['Success', 'Failed', 'Cancelled', 'TimedOut']:
print("Command completed.")
print(f"Output: {result['StandardOutputContent']}")
return {
'statusCode': 200,
'body': f"Command Output: {result['StandardOutputContent']}"
}
print("Command timed out.")
return {
'statusCode': 500,
'body': "Command did not complete in time."
}
except Exception as e:
print(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': f"Error: {str(e)}"
}- 결과: Lambda 함수 테스트 실행 (비어있는 json 파일 {) 로 테스트) Lambda → SSM → EC2 연결 성공!

④ S3 이벤트 트리거 → Lambda → SSM API → EC2 → 스크립트 실행 테스트
- 목표
- S3 이벤트 → Lambda 호출
- Lambda → SSM API 호출 → EC2 인스턴스에 명령 전달
- EC2 내 파이썬 스크립트 실행 시도 확인
- Lambda 함수 코드 변경
import boto3
def lambda_handler(event, context):
ssm = boto3.client('ssm', region_name='ap-northeast-2')
try:
print("Sending SSM command to EC2...")
response = ssm.send_command(
InstanceIds=['i-xxx'], # EC2 인스턴스 ID
DocumentName='AWS-RunShellScript',
Parameters={
'commands': [
"eval \"$(/home/ubuntu/miniconda3/bin/conda shell.bash hook)\" && conda activate neo4j_env",
"python3 /home/ubuntu/json_to_neo4j.py"
]
}
)
# Command ID 반환
command_id = response['Command']['CommandId']
print(f"Command ID: {command_id}")
return {
'statusCode': 200,
'body': f"SSM Command successfully sent. Command ID: {command_id}"
}
except Exception as e:
print(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': f"Error: {str(e)}"
}- S3 버킷(big9-project-02-roadmap-bucket/roadmap_2022)에 test.json 업로드
- 테스트 결과 확인1: CloudWatch 로그 SSM 명령이 성공적으로 전송됨 (Command ID 생성)

- 테스트 결과 확인2: SSM Agent 로그

⑤ json_to_neo4j.py 실행 → neo4j 데이터 적재
- EC2 내 Python 스크립트(json_to_neo4j.py) 수정
# json_to_neo4j.py
import json
import os
import openai
import boto3
import pickle
from neo4j import GraphDatabase
from dotenv import load_dotenv
# .env 파일에서 환경 변수 로드
load_dotenv()
# Neo4j 연결 설정
uri = os.getenv("NEO4J_URI")
username = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
# S3 연결 설정
aws_access_key = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
s3_bucket = os.getenv("S3_BUCKET_NAME")
region_name = os.getenv("AWS_REGION")
# OpenAI API 설정
openai.api_key = os.getenv("OPENAI_API_KEY")
# 클라이언트 및 세션 생성
s3_client = boto3.client(
"s3",
aws_access_key_id=aws_access_key,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name,
)
driver = GraphDatabase.driver(uri, auth=(username, password))
session = driver.session()
# 벡터 생성 함수 (OpenAI API 사용)
def generate_vector(text):
response = openai.Embedding.create(model="text-embedding-ada-002", input=text)
return response["data"][0]["embedding"]
# 벡터 파일 저장 함수
def save_vector_to_file(name, vector):
vector_path = f"/tmp/vectors/{name.replace(' ', '_')}.pkl" # 공백을 밑줄로 교체
os.makedirs("/tmp/vectors", exist_ok=True)
with open(vector_path, "wb") as f:
pickle.dump(vector, f)
return vector_path
# 노드 생성 및 관계 설정 함수
def create_node_and_relationship(
name, parent_name=None, node_type=None, vector_path=None
):
node_type = node_type
# 노드 생성
query = f"""
MERGE (n:{node_type} {{name: $name}})
"""
if vector_path: # 벡터 경로가 있을 경우 추가 속성 설정
query += """
SET n.vector_path = $vector_path
"""
session.run(query, name=name, vector_path=vector_path)
print(f"Node created: {name} ({node_type})")
# 부모 노드와의 관계 설정
if parent_name:
query_relationship = """
MATCH (p {name: $parent_name})
MATCH (n {name: $name})
MERGE (p)-[:HAS_CHILD]->(n)
"""
session.run(query_relationship, name=name, parent_name=parent_name)
print(f"Relationship created: {parent_name} -> {name}")
# JSON 데이터 처리 함수 (벡터 추가 포함)
def process_json_data(data, parent_name=None, node_type="Category"):
for key, value in data.items():
if (
isinstance(value, dict) and "name" in value
): # 값이 dict이며 'name' 키가 존재할 경우
item_name = value["name"]
# 벡터 생성 후 파일에 저장
vector = generate_vector(item_name)
vector_path = save_vector_to_file(item_name, vector)
# 노드 및 관계 생성
create_node_and_relationship(
item_name,
parent_name=parent_name,
node_type=node_type,
vector_path=vector_path,
)
# 자식 항목 처리
if "children" in value:
process_json_data(
value["children"], parent_name=item_name, node_type="Branch"
)
elif isinstance(value, str): # 값이 문자열일 경우 (Leaf 노드)
# 벡터 생성 후 파일에 저장
vector = generate_vector(value)
vector_path = save_vector_to_file(value, vector)
# 노드 및 관계 생성
create_node_and_relationship(
value,
parent_name=parent_name,
node_type="Leaf",
vector_path=vector_path,
)
# JSON 파일 다운로드 및 처리 함수
def process_s3_json(s3_key):
temp_file = "/tmp/temp_json_file.json"
s3_client.download_file(s3_bucket, s3_key, temp_file)
print(f"Downloaded {s3_key} to {temp_file}")
with open(temp_file, "r", encoding="utf-8") as file:
data = json.load(file)
for key, value in data.items():
category_name = value["name"]
# 벡터 생성 후 파일에 저장
vector = generate_vector(category_name)
vector_path = save_vector_to_file(category_name, vector)
# 대분류 노드 생성 (벡터 경로 포함)
create_node_and_relationship(
category_name, node_type="Category", vector_path=vector_path
)
# 자식 항목 처리
if "children" in value:
process_json_data(
value["children"],
parent_name=category_name,
node_type="Subcategory",
)
# S3의 JSON 파일 리스트
s3_keys = [
"roadmap_2022/01_num_cal.json",
"roadmap_2022/02_change_of_relationship.json",
"roadmap_2022/03_shape_meas.json",
"roadmap_2022/04_data_and_possibility.json",
]
# JSON 파일 처리
try:
for s3_key in s3_keys:
process_s3_json(s3_key)
print("All JSON files have been successfully processed and inserted into Neo4j.")
except Exception as e:
print(f"Error processing JSON files: {e}")
finally:
session.close()- .env 수정
# .env
# Neo4j 정보
NEO4J_URI=bolt://<YOUR_NEO4J_HOST>:7687
NEO4J_USERNAME=xxx
NEO4J_PASSWORD=xxx
# S3 정보
AWS_ACCESS_KEY_ID=xxx
AWS_SECRET_ACCESS_KEY=xxx
S3_BUCKET_NAME=xxx
AWS_REGION=ap-northeast-2- S3 버킷 > roadmap_2022 폴더에 json 파일 4개 업로드
- 01_num_cal.json
- 02_change_of_relationship.json
- 03_shape_meas.json
- 04_data_and_possibility.json
- S3 이벤트 트리거 → Lambda가 SSM 명령을 정상적으로 보내는지 확인
- Lambda CloudWatch 로그 확인
- 4개 json 파일 업로드 → 4개 로그 생성
- Lambda CloudWatch 로그 확인


- Lambda에서 SSM을 통해 실행된 파이썬 스크립트 로그 확인
- CloudWatch의 Command ID 활용
- SSM 명령 실행 성공시
- ResponseCode: 0
- Status: Success
- S3에서 JSON 파일 다운로드 성공시
- StandardOutputContent에 다운로드 메세지 출력: Downloaded roadmap_2022/01_num_cal.json from big9-project-02-roadmap-bucket to /tmp/temp_json_file.json
aws ssm get-command-invocation \
--command-id "COMMAND_ID" \
--instance-id "EC2_INSTANCE_ID" \
--region ap-northeast-2
"""
{
"CommandId": "XXX",
"InstanceId": "i-XXX",
"Comment": "",
"DocumentName": "AWS-RunShellScript",
"DocumentVersion": "$DEFAULT",
"PluginName": "aws:runShellScript",
"ResponseCode": 0,
"ExecutionStartDateTime": "2024-12-16T14:19:54.528Z",
"ExecutionElapsedTime": "PT16.215S",
"ExecutionEndDateTime": "2024-12-16T14:20:10.528Z",
"Status": "Success",
"StatusDetails": "Success",
"StandardOutputContent": "Downloaded roadmap_2022/01_num_cal.json from big9-project-02-roadmap-bucket to /tmp/temp_json_file.json\nDownloaded roadmap_2022/02_change_of_relationship.json from big9-project-02-roadmap-bucket to /tmp/temp_json_file.json\nDownloaded roadmap_2022/03_shape_meas.json from big9-project-02-roadmap-bucket to /tmp/temp_json_file.json\nDownloaded roadmap_2022/04_data_and_possibility.json from big9-project-02-roadmap-bucket to /tmp/temp_json_file.json\n",
"StandardOutputUrl": "",
"StandardErrorContent": "",
"StandardErrorUrl": "",
"CloudWatchOutputConfig": {
"CloudWatchLogGroupName": "",
"CloudWatchOutputEnabled": false
}
}
"""- Neo4j에 데이터가 적재되었는지 확인
- Neo4j Desktop 실행 → Remote Connection
- Neo4j Browser의 cypher-shell에 노드 확인 쿼리 입력
# cyhper
MATCH (n) RETURN n LIMIT 50;
- 데이터 관계가 제대로 생성되었는지 확인하는 쿼리 입력
# cypher
MATCH (p)-[:HAS_CHILD]->(c) RETURN p, c LIMIT 10;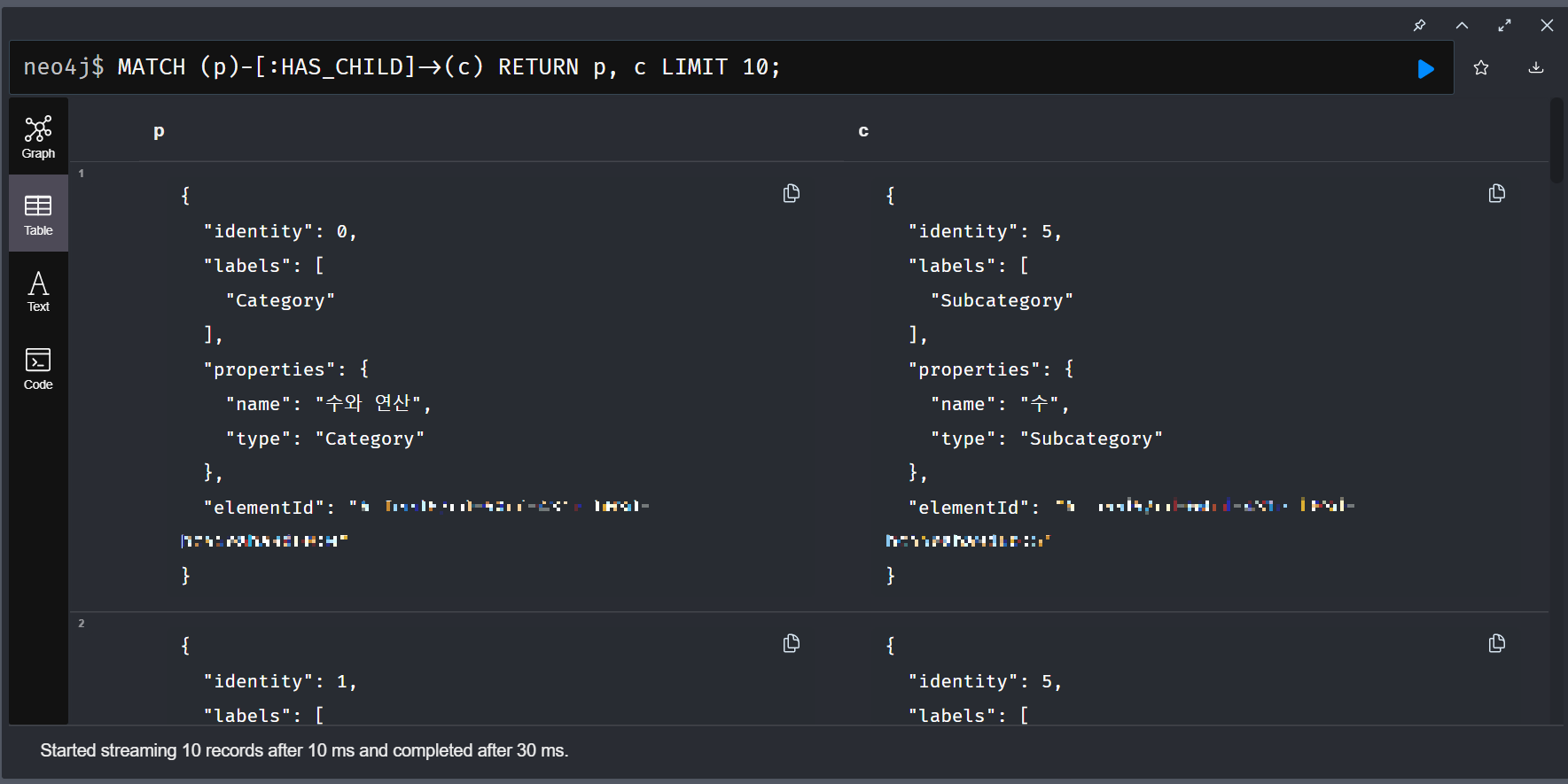
- 노드 그래프 확인
# cypher
# 노드 그래프 확인
MATCH (n)-[r]->(m)
RETURN n, r, m
# 데이터 전부 삭제
MATCH (n)
DETACH DELETE n
📙 내일 일정
- 최종 프로젝트

'TIL _Today I Learned > 2024.12' 카테고리의 다른 글
| [DAY 104] 최종 프로젝트_ 인터넷 게이트웨이, 라우팅 테이블, ACL (0) | 2024.12.16 |
|---|---|
| [DAY 103] 최종 프로젝트_ CI/CD Pipeline (0) | 2024.12.13 |
| [DAY 101] 최종 프로젝트_ 네트워크 (2) | 2024.12.11 |
| [DAY 100] 최종 프로젝트_ GitLab (1) | 2024.12.10 |
| [DAY 99] 최종 프로젝트_ AWS 아키텍처 설계 (4) | 2024.12.09 |



