[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.12.04
📕 프로젝트 작업 내역
- 프로젝트 워크플로 작성
📗 수행 결과
1. 프로젝트 목표
초등학생 수학 학습 데이터 입력시, KST 알고리즘에 사용할 수 있는 자동 라벨링 프로그램 개발
- MLOps 지식과 CI/CD 프로세스를 이해하고, 이를 바탕으로 자동화 파이프라인 제작
2. 기대 효과
- 정확성 향상: RAG 검색과 LLM 라벨링의 결합으로 더 정확한 라벨링 가능
- 유연성 증대: 다양한 문제 유형에 대한 대응 가능
- 자동화: 사용자 피드백 수집부터 모델 개선까지 대부분의 과정이 자동화
3. 아키텍처 흐름
1) 사용자 문제 입력 → RAG 검색 → LLM 라벨링
2) 결과 신뢰도 분석
3) 신뢰도가 낮으면 수정, 높으면 결과 반환
4)사용자 피드백 수집 → 데이터 저장 → 모델 Fine-Tuning

① 데이터 수집 및 RAG 검색
- 사용자가 입력한 문제 텍스트를 기반으로 핵심 키워드를 추출한 뒤, 이를 검색 엔진에서 처리하여 관련 데이터를 가져옴
- 예를 들어, "100 이하의 수를 읽고 쓰세요."라는 문제를 입력하면, 관련된 학습 지도표와 예제 데이터를 검색
② LLM 라벨링
- RAG 검색 결과와 함께 문제를 LLM에 입력하여 라벨링 결과를 도출
- 결과는 "대분류: 수와 연산", "중분류: 네 자리 이하의 수", "하위 분류: [2수01-01-A]"와 같은 형식으로 반환
③ 신뢰도 분석
- LLM의 출력이 신뢰도가 높은지 점검. 예를 들어, 검색 결과와 LLM 출력의 유사도를 점수화(코사인 유사도 등)하여 분석
- 신뢰도가 낮으면 기존 데이터베이스와 비교하거나 RAG 검색 데이터를 재활용해 수정
④ 사용자 피드백 및 모델 개선
- 결과에 대한 사용자 피드백을 받아, 피드백 데이터를 수집 및 저장
- 이를 Fine-Tuning 과정에 활용해 모델의 성능을 지속적으로 개선
⑤ 자동화 루프
- 피드백 수집 → 데이터베이스 업데이트 → Fine-Tuning → 결과 개선의 순환 구조를 통해 시스템이 점진적으로 발전
4. 주요 기능과 구성 요소
1) RAG (Retrieval-Augmented Gerneration) 적용
① 데이터 준비
- 지식 베이스 구축
- 학습 로드맵 + 문제 데이터 → 데이터베이스 구축* → 검색 엔진(FAISS, ElasticSearch 등)을 사용하여 데이터 인덱싱 * JSON 데이터는 관계형 데이터베이스(MySQL, PostgreSQL)에 저장하려면 테이블을 여러개 만들어서 분리해야 함. 하지만 MongoDB는 JSON을 그대로 저장∙검색할 수 있어 비정형 데이터를 효율적으로 처리할 수 있음
[tip] JSON 데이터 "비정형 데이터"
- 비정형 데이터: 고정된 스키마(테이블 구조)로 정의되지 않는 데이터
• ex: 텍스트, 이미지, 동영상, JSON 데이터 등
[tip] NoSQL: 비정형 데이터를 처리하기 위해 설계된 데이터베이스 시스템
- 스키마가 고정되지 않아 데이터 구조를 자유롭게 저장 가능
- 확장성이 높고, 대규모 데이터를 빠르게 처리할 수 있음
- 대표적인 NoSQL 시스템 중 하나가 MongoDB
[tip] MongoDB
- JSON 형식과 유사한 BSON(Binary JSON)으로 데이터를 저장
- 데이터가 계층 구조(중첩 구조)를 가질 수 있어, 위의 JSON 데이터를 바로 저장 가능
- ex: 위 데이터를 MongoDB에 저장하면 별도 테이블 분리 없이 중첩된 구조로 저장됨
# json
[
{
"id": "1",
"content": "100 이하의 수를 읽고 쓰세요.",
"category": {
"대분류": "수와 연산",
"중분류": "네 자리 이하의 수",
"하위 분류": "[2수01-01-A]"
}
},
{
"id": "2",
"content": "소수와 합성수를 분류하세요.",
"category": {
"대분류": "수와 연산",
"중분류": "소수와 합성수",
"하위 분류": "[2수02-02-B]"
}
}
]
② 검색 모듈 구성
- 키워드 추출
- 사용자가 입력한 문제 텍스트에서 핵심 키워드를 추출
- Python의 spaCy와 Konlpy를 사용하여 한국어 키워드 추출
from konlpy.tag import Okt
text = "100 이하의 수를 읽고 쓰세요."
okt = Okt()
keywords = okt.nouns(text) # ['100', '수', '읽기']- FAISS 또는 ElasticSearch 설정
- 학습 데이터를 인덱싱하여 검색 가능한 구조로 저장
- 검색 키워드와 가장 유사한 데이터를 반환
from sentence_transformers import SentenceTransformer
import faiss
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
data = ["100 이하의 수를 읽고 쓰세요.", "소수와 합성수를 분류하세요."]
embeddings = model.encode(data)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
query = "100 이하의 수"
query_embedding = model.encode([query])
distances, indices = index.search(query_embedding, k=1)
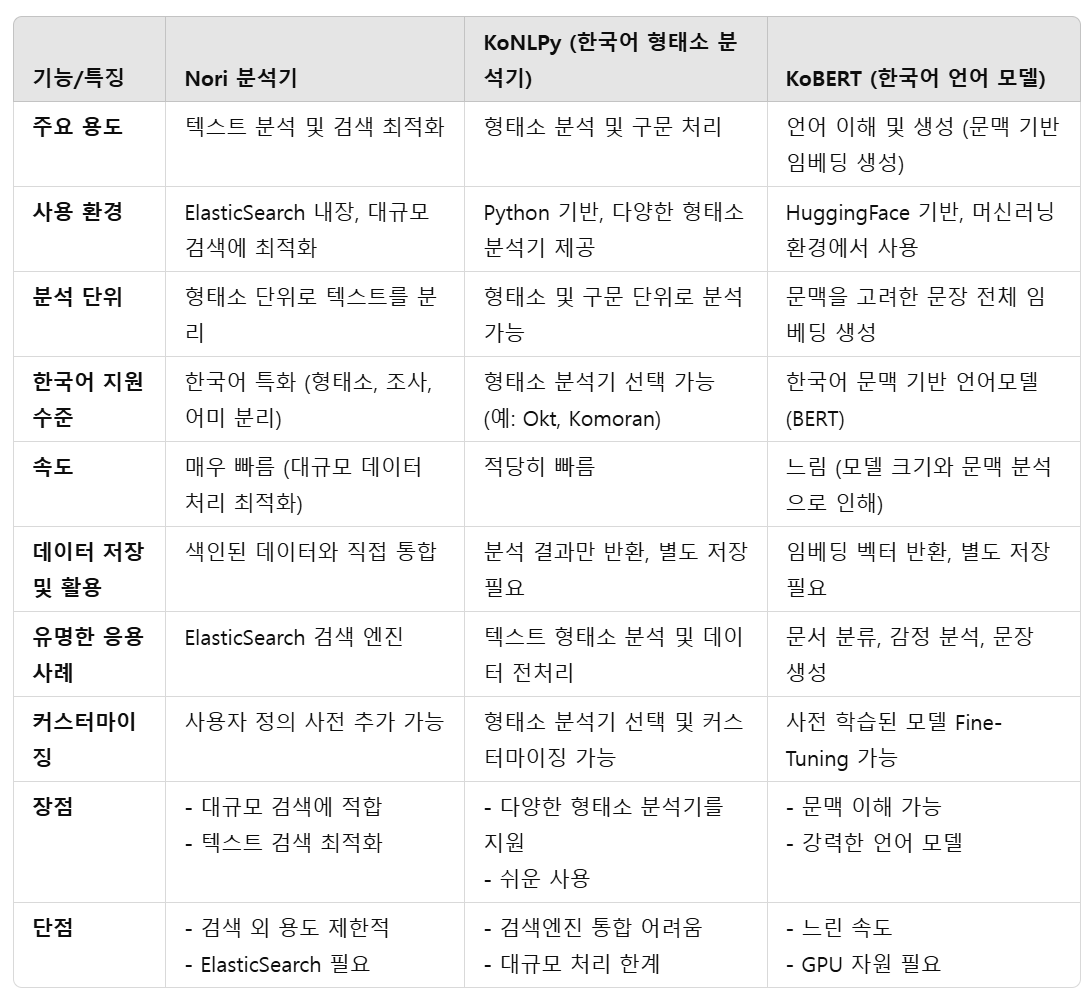
print(f"가장 유사한 데이터: {data[indices[0][0]]}")* ElasticSearch 사용시, 한국어 형태소 분석기 Nori 사용
1) 검색 엔진에 입력할 json 데이터 형태소 분석
2) RAG에 입력되는 수학 문제를 형태소 분석
3) 1)과 2)를 매칭(TF-IDF 같은 유사도 분석 이용)하여 가장 유사도가 높은 1)을 반환
③ 검색 결과와 LLM 결합
- LLM Prompt 구성
- RAG에서 검색된 데이터를 포함하여 LLM에 전달
문제를 분석하여 다음 형식으로 반환하세요:
- 대분류: (예: 수와 연산)
- 중분류: (예: 네 자리 이하의 수)
- 하위 분류: (예: [2수01-01-A])
문제: "100 이하의 수를 읽고 쓰세요."
참고 자료: "네 자리 이하의 수에 대한 학습 지도표."- LLM 실행
- Hugging Face의 transformers 라이브러리를 사용하여 문제를 라벨링
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "huggingface/ko-llm"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
input_text = """
문제를 분석하여 다음 형식으로 반환하세요:
- 대분류: (예: 수와 연산)
- 중분류: (예: 네 자리 이하의 수)
- 하위 분류: (예: [2수01-01-A])
문제: "100 이하의 수를 읽고 쓰세요."
참고 자료: "네 자리 이하의 수에 대한 학습 지도표."
"""
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
2) AI Agent 적용
[tip] LLM 이란?
- LLM은 대규모 언어 모델로, 방대한 양의 텍스트 데이터를 학습하여 언어의 구조와 문맥을 이해하고, 주어진 입력에 대해 텍스트를 생성하는 인공지능 모델
- 대표적인 LLM으로는 GPT, BERT, T5 등이 있으며, 이번 프로젝트에서는 한국어 모델(Hugging Face 모델 등)을 활용함
[tip] RAG 이란?
- RAG는 검색 기반 생성 모델로, 입력된 질문이나 문제에 대해 외부 지식(검색 결과)을 활용해 답변을 생성하는 AI 기술
- 기존의 LLM이 정적인 학습 데이터에 의존해 답변을 생성하는 것과 달리, RAG는 실시간 검색을 통해 더 정확하고 최신의 정보를 반영할 수 있음
[tip] AI Agent란?
- RAG(Search + Generation) 및 LLM(Large Language Model) 결과를 기반으로 한 결과 검증, 수정, 학습, 자동화를 수행하는 지능형 시스템
- 즉, 사용자 피드백과 기존 데이터베이스를 활용해 지속적으로 모델을 개선하고, 문제 해결의 신뢰도와 정확성을 높이는 역할을 담당
2-1) AI Agent 구성
① 구성 요소
- 추론 엔진: RAG와 LLM 결과를 검증 및 결합
- 피드백 학습: 사용자 피드백 데이터를 저장하고 Fine-Tuning에 반영
- 자동화 루프: 데이터 수집 → 모델 업데이트 → 결과 개선
② AI Agent 논리 흐름
- RAG 결과와 LLM 라벨링 결과 비교
- 불일치 시
- 기존 데이터베이스와 비교하여 수정
- 사용자 피드백을 학습 데이터에 추가
- 모델 Fine-Tuning 주기를 설정하여 정기적으로 업데이트
2-2) 피드백 수집 및 활용
① 피드백 저장
- 사용자 피드백을 JSON 형태로 저장
{
"problem_id": 101,
"correct_labels": {
"대분류": "수와 연산",
"중분류": "네 자리 이하의 수",
"하위 분류": "[2수01-01-B]"
}
}
② Fine-Tuning에 반영
- 사용자 피드백 데이터를 학습 데이터에 추가하여 모델 재학습
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
num_train_epochs=3
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=feedback_dataset
)
trainer.train()
5. 프로젝트 내 MLOps, CI/CD
1) MLOps란?
MLOps는 Machine Learning Operations의 약자로, 머신러닝 시스템 개발, 배포, 운영 및 유지보수를 자동화하는 프로세스
- 목표: 모델 개발, 학습, 테스트, 배포 및 모니터링까지 전 주기를 효율적이고 반복 가능하게 만드는 것
- 핵심 구성 요소
- 모델 개발(코드 관리): 데이터 전처리, 학습, 평가
- 모델 배포(배포 관리): 학습된 모델을 프로덕션 환경에 배포
- 모니터링 및 유지보수: 운영 중인 모델의 성능 모니터링, 성능 저하 시 재학습
2) CI/CD란?
- CI (Continuous Integration)
- 코드 변경 사항을 지속적으로 통합하고 자동으로 테스트하여 문제를 조기에 발견
- 데이터 전처리 코드, 모델 학습 코드, API 코드 등 모든 부분에서 코드의 품질을 유지
- CD (Continuous Deployment/Delivery)
- 새로운 버전의 모델, 데이터, 코드 등을 자동으로 프로덕션 환경에 배포
- Continuous Delivery: 배포 전 최종 승인을 요구
- Continuous Deployment: 변경 사항이 테스트를 통과하면 자동으로 배포
3) 프로젝트에서 MLOps와 CI/CD의 역할
3-1) 학습 로드맵 + 문제 데이터 → 데이터베이스 구축
- MLOps 역할
- 데이터 관리: 데이터가 학습 로드맵 및 문제 데이터(JSON 형태)로 수집되는 단계
- 데이터 버전 관리: 데이터가 변경되었을 때 데이터셋의 버전을 관리하여 추적 가능
- 데이터 품질 확인: 데이터 수집 시 자동으로 데이터 품질 테스트 실행(CI)
- 데이터 준비 자동화: 데이터 전처리 파이프라인 구축 및 자동 실행
- 예를 들어, 새 데이터를 MongoDB에 추가하기 전, 특정 조건(예: JSON 스키마 검증, 중복 데이터 제거)을 확인하는 테스트 실행
- CI/CD 역할
- 데이터 관련 스크립트 테스트
- 데이터 처리 및 DB 인덱싱 코드를 지속적으로 테스트(CI)
- 데이터 수집과 데이터베이스로의 업로드 스크립트를 배포(CD)
3-2) 검색 엔진(FAISS, ElasticSearch 등)을 사용한 데이터 인덱싱
- MLOps 역할
- 검색 파이프라인 관리: RAG(Search + Generation)에서 검색 엔진(FAISS, ElasticSearch 등)을 사용하는 단계
- 검색 파이프라인 자동화: 데이터베이스에서 검색 인덱스를 자동 생성 및 업데이트
- 검색 결과 품질 모니터링: 검색된 데이터가 사용자 입력에 적합한지 성능 평가
- 인덱싱 파이프라인 버전 관리: 검색 엔진 업데이트 시에도 일관성 유지
- CI/CD 역할
- 검색 엔진 코드 배포
- 검색 엔진이 사용하는 코드를 통합 및 테스트(CI)
- 데이터베이스와 검색 엔진의 연결을 자동으로 업데이트하거나 배포(CD)
3-3) LLM 라벨링
- MLOps 역할
- 모델 학습 및 배포
- LLM을 사용해 문제를 라벨링하는 단계
- 모델 학습 파이프라인 관리
- LLM 학습 데이터 준비 → 학습 → 평가의 전체 파이프라인 자동화
- Fine-Tuning이 필요한 경우에도 기존 학습 데이터를 재활용해 새 데이터를 쉽게 추가
- 모델 배포 및 모니터링
- 학습된 LLM 모델을 API 형태로 배포(예: Hugging Face 모델 활용)
- 프로덕션 환경에서 모델의 성능 모니터링 및 롤백 기능 제공
- CI/CD 역할
- 라벨링 코드와 모델 배포
- 라벨링에 사용하는 LLM 모델 코드 통합 및 자동 테스트(CI)
- Fine-Tuning한 모델을 자동 배포(CD)
3-4) 신뢰도 분석 및 결과 반환
- MLOps 역할
- 시스템 성능 모니터링
- LLM의 출력 신뢰도를 평가(예: 코사인 유사도 계산)하고 결과가 적합한지 확인
- 프로덕션 환경에서 모델 성능이 저하되었을 경우, 알림 전송 및 새 모델 배포 준비
- 실시간 추론 속도 및 API 응답 시간을 지속적으로 모니터링
- CI/CD 역할
- 신뢰도 분석 코드 관리
- 신뢰도 분석 스크립트와 API 코드의 통합 및 테스트(CI)
- 신뢰도 분석 알고리즘 업데이트를 프로덕션 환경에 배포(CD)
3-5) 사용자 피드백 수집 및 Fine-Tuning
- MLOps 역할
- 지속적인 모델 개선
- Fine-Tuning 데이터 관리
- 사용자 피드백 데이터를 저장하고 학습 데이터셋으로 변환
- 피드백 데이터를 기존 학습 데이터와 병합하여 새 학습 데이터셋 생성
- Fine-Tuning 파이프라인 자동화
- 새 데이터를 기반으로 모델 재학습
- 새로 학습된 모델을 평가 후 성능이 개선된 경우 배포
- Fine-Tuning 데이터 관리
- CI/CD 역할
- 피드백 반영 및 모델 업데이트
- Fine-Tuning 파이프라인을 자동으로 실행(CI)
- Fine-Tuning된 모델을 프로덕션에 자동 배포(CD)
4) MLOps와 CI/CD 요약
- MLOps: 프로젝트 전반에 걸쳐 데이터 관리, 모델 학습 및 배포, 시스템 모니터링을 자동화하여 머신러닝 파이프라인의 안정성을 보장
- CI/CD: 모든 코드와 모델(데이터 처리, 검색, 라벨링 등)을 지속적으로 통합(CI) 및 배포(CD)하여 효율적이고 안정적인 프로덕션 운영을 지원
[tip] 전체 과정에서 MLOps와 CI/CD의 위치
- MLOps
• 데이터 준비 → 데이터 인덱싱 → 모델 학습 → 모델 배포 → 성능 모니터링 및 개선까지 전 과정
- CI/CD
• 데이터 처리 코드, 검색 엔진 코드, 모델 학습 코드, API 코드의 지속적 테스트(CI)와 자동 배포(CD)
📙 내일 일정
- 최종 프로젝트

'TIL _Today I Learned > 2024.12' 카테고리의 다른 글
| [DAY 99] 최종 프로젝트_ AWS 아키텍처 설계 (1) | 2024.12.09 |
|---|---|
| [DAY 98] 최종 프로젝트_ 모델 Fine Tuning, 플로우 차트 (2) | 2024.12.06 |
| [DAY 97] 최종 프로젝트_ GraphRAG, MLOps, CI/CD (0) | 2024.12.05 |
| [DAY 95] 최종 프로젝트_ KST와 IRT 통합 (1) | 2024.12.03 |
| [DAY 94] 최종 프로젝트_ KST 알고리즘 기반 학습 결손 진단 시스템 설계 (0) | 2024.12.02 |



