[천재교육] 프로젝트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.09.10
📕 학습 목록
- 오픈소스 딥러닝 프레임워크
- Hugging Face
- 부동소수점
- YOLO Model
- CPU / GPU / 클라우드 기반 GPU
📗 기억할 내용
1) 오픈소스 딥러닝 프레임워크
① 정의
- 개발자가 딥러닝 모델을 개발하고 훈련하는 데 필요한 도구∙라이브러리를 제공하는 무료 소프트웨어 플랫폼
② 종류
| 오픈소스 딥러닝 프레임워크 | ||||
| 프레임워크 종류 | TensorFlow | PyTorch | MXNet | CNTK |
| 개발사/ 커뮤니티 | Meta (Facebook) | Apache Software | Microsoft | |
| 특징 | 높은 확장성, 대규모 배포 및 생산 환경에 강력함. Keras가 고수준 API로 포함됨 | 동적 그래프, 연구에 적합. 과거 Torch를 기반으로 발전. 직관적 사용성 | 대규모 분산 학습에 강점, 멀티 GPU/CPU 학습 지원 | 대규모 데이터 학습에 적합, 분산 학습 지원 |
| 사용 언어 | Python, C++ | Python, C++ | Python, C++ | Python, C++, BrainScript |
| 주요 사용 분야 | 컴퓨터 비전, NLP, 분산 학습 | 연구 및 실험, 컴퓨터 비전, NLP | 대규모 분산 학습, 클라우드 기반 학습 | 음성 인식, 대규모 데이터 처리 |
2) Hugging Face
① 정의
- 딥러닝 모델, 데이터를 오픈소스로 제공하는 플랫폼
- 자연어 처리(NLP), 컴퓨터 비전(CV), 이미지 생성 등의 딥러닝 작업을 위한 모델, 데이터셋, 라이브러리를 제공 *CV : 컴퓨터가 이미지나 영상을 이해하고 해석할 수 있게 만드는 기술
- PyTorch와 TensorFlow 같은 오픈소스 딥러닝 프레임워크에서 사용되는 라이브러리, 모델, 데이터셋을 제공
② Hugging Face에서 제공하는 주요 기능
- 라이브러리 : 라이브러리를 통해 Hugging Face의 모델 허브에서 다양한 사전 학습된 모델 or 데이터셋을 불러와 쉽게 적용할 수 있게함
| Hugging Face에서 제공하는 오픈소스 라이브러리 | |||
| Transformers | Diffusers | Datasets | |
| 목적 | 자연어 처리(NLP), 컴퓨터 비전(CV), 음성 인식 등 다양한 딥러닝 모델을 쉽게 사용할 수 있도록 지원 | Diffusion 기반 이미지 생성 모델을 위한 파이프라인 제공 | 다양한 딥러닝 데이터셋을 불러오고 처리할 수 있도록 지원 |
| 주요 지원 모델 | BERT, GPT, T5, ViT, CLIP 등 | Stable Diffusion, Imagen 등 | NLP, 컴퓨터 비전, 음성 데이터셋 등 |
| 기능 | 사전 학습된 Transformer 모델을 쉽게 불러와 훈련 및 추론 가능 | 텍스트 기반의 이미지 생성 및 수정 작업 지원 | 다양한 데이터셋을 손쉽게 로드하고 전처리 가능 |
| 필수 환경 | PyTorch or TensorFlow | PyTorch | PyTorch or TensorFlow |
| 사용 방법 | 모델 허브에서 사전 학습된 모델을 다운로드 받아 쉽게 사용 | 모델 이름을 입력해 해당 모델을 사용, 체크포인트* 변경 가능 | Hugging Face Datasets 라이브러리를 통해 데이터 로드 |
| 특징 | NLP와 CV에서 가장 널리 사용되는 Transformer 기반 모델 제공 | 프롬프트* 기반 이미지 생성, 체크포인트를 통해 다른 스타일 적용 가능 | 대규모 데이터셋에 대해 효율적인 메모리 사용과 빠른 처리 제공 |
| 주요 활용 분야 | 텍스트 생성, 번역, 질문 응답, 이미지 분류 등 | 이미지 생성, 이미지 수정, 스타일 변경 | NLP, CV, 음성 인식, 강화 학습 등의 학습용 데이 |
* (모델) 체크포인트 : 훈련된 모델의 특정 상태를 저장한 파일. 이 파일을 불러오면 특정 스타일의 이미지를 생성할 수 있음
* (텍스트) 프롬프트 : 생성하려는 이미지의 설명을 입력하는 방식으로 사용됨
- 모델 허브(Model Hub) : NLP, 컴퓨터 비전, 음성 인식 등 다양한 분야의 모델들이 포함되어 있음
- 자연어 처리(NLP) 모델 : BERT, GPT, T5,
- 이미지 생성 및 컴퓨터 비전 관련 모델 : Stable Diffusion, CLIP
- 음성 인식 모델 : Whisper
| Hugging Face에서 제공하는 오픈소스 모델 허브 | ||||||
| BERT | GPT-3 | T5 | Stable Diffusion | CLIP | Whisper | |
| 모델 유형 | Transformer (NLP) | Transformer (NLP) | Transformer (NLP) | Diffusion 모델 | Transformer (멀티모달) | 음성 인식 모델 |
| 주된 용도 | 텍스트 분류, 질문 응답, 번역 등 | 텍스트 생성, 대화, 번역, 요약 등 | 텍스트 생성, 번역, 질문 응답, 텍스트 요약 | 이미지 생성 및 편집 | 이미지-텍스트 매칭, 이미지 검색 | 음성 인식, 음성-텍스트 변환 |
| 특징 | 문맥과 의미를 이해하여 자연어 처리에서 뛰어난 성능 | 대규모 언어 모델로 자연스러운 텍스트 생성 가능 | 텍스트 변환 문제로 통일하여 다양한 NLP 작업에서 사용 | 노이즈 추가 및 제거를 반복해 주어진 텍스트 프롬프트에 맞는 이미지를 생성 | 텍스트와 이미지의 연관성 학습 | 다국어 음성 인식 가능 |
| 주요 활용 분야 | 자연어 처리 (NLP) | 자연어 생성, 텍스트 기반 작업 | 텍스트 생성, 번역, 요약 등 다양한 NLP 작업 | 이미지 생성, 이미지 수정 | 텍스트-이미지 검색, 분류 작업 | 음성 인식, 번역 |
- 데이터셋 허브 (Dataset Hub) : Datasets 라이브러리를 통해 대규모 데이터셋을 쉽게 불러오고, 처리할 수 있음
- 자연어 처리(NLP) 데이터셋
- 이미지 및 컴퓨터 비전 데이터셋
- 음성 데이터셋
③ 주요 모델의 구조
- Stable Diffusion 모델
- 텍스트 프롬프트를 입력받아 이미지를 생성하는 딥러닝 모델의 구조
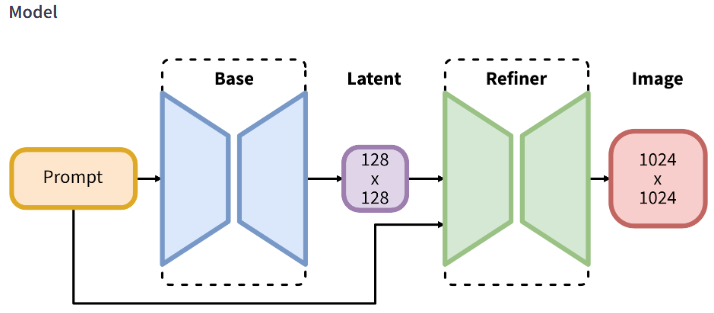
- Prompt (프롬프트) : 사용자가 입력하는 텍스트 명령. 예를 들어, "A cat sitting on a chair" 같은 텍스트 입력을 통해 생성하려는 이미지의 내용을 전달함. 이 프롬프트는 모델이 어떤 이미지를 생성해야 하는지에 대한 정보를 제공함
- Base (베이스) : Base 모델은 입력된 텍스트 프롬프트를 기반으로 기본적인 이미지의 잠재 표현(latent representation)을 생성하는 역할. 이 단계에서는 이미지가 실제로 생성되지는 않지만, 텍스트 프롬프트로부터 추출된 특징을 잠재 공간(latent space)에서 표현함. 여기서는 128x128 크기의 잠재 표현이 생성됨
- Latent (잠재 공간) : 이 부분은 모델이 생성한 잠재 변수(latent variables)를 나타냄. 즉, 프롬프트를 통해 생성된 128x128의 잠재 이미지 표현임. 이 잠재 표현은 디퓨전 모델의 특성상 아직 완성된 이미지가 아니며, 이후의 과정을 통해 점차 실제 이미지로 변환됨
- Refiner (리파이너) : 리파이너 모델은 잠재 표현에서 얻은 정보를 기반으로 이미지를 고해상도로 세밀하게 수정하는 역할. 잠재 표현을 더 세밀하게 해석하고, 그 결과물로 고해상도(1024x1024) 이미지를 생성함. Stable Diffusion처럼 이미지를 생성하는 많은 모델에서 고해상도 이미지를 얻기 위한 후처리 단계에 해당함
- Image (이미지) : 최종 출력인 1024x1024 크기의 이미지. 리파이너 모델을 거쳐 잠재 표현에서 최종적으로 사용자가 입력한 프롬프트에 맞는 완성된 이미지가 생성됨
- Vision Transformer (ViT) 모델
- Transformer 아키텍처를 이미지 처리에 적용한 모델. 이미지 분류와 같은 시각적 작업을 위해 설계되었으며, 기존의 CNN(Convolutional Neural Network) 대신 Transformer 구조를 사용함

- 이미지 패치 분할 : 이미지를 고정된 크기의 패치(patch)로 나눔. 일반적으로 16x16 크기의 패치로 분할되며, 이 과정은 마치 이미지를 작은 조각들로 쪼개는 것과 같음. 각 패치는 1차원 벡터로 변환되어 Transformer 모델에 입력됨. 즉, 이미지를 한 번에 처리하는 것이 아니라 작은 패치들을 처리하는 방식
- Patch + Position Embedding : 각 패치에 위치 정보(position embedding)를 추가. Transformer는 원래 순서에 민감하지 않은 모델이므로, 이미지에서 각 패치의 위치 정보를 함께 입력하여 각 패치가 이미지의 어느 부분에 해당하는지 모델이 알 수 있도록 함. 이 단계에서는 추가로 classification token이 학습 가능한 형태로 삽입되며, 최종적으로 이 토큰이 이미지 분류 결과를 도출하는 데 사용됨
- Linear Projection of Flattened Patches : 각 패치(16x16)는 1차원 벡터로 변환됨. 이 변환된 패치는 Linear Projection을 통해 차원이 맞춰지고, Transformer Encoder에 입력될 수 있는 형식으로 변환됨
- Transformer Encoder : Transformer의 Encoder는 입력받은 패치들의 벡터를 처리. 일반적으로 Multi-Head Attention과 MLP(다층 퍼셉트론) 구조가 포함되어 있으며, Layer Normalization을 적용해 수치 안정성을 유지함. Transformer Encoder는 원래 NLP에서 사용되던 구조로, 각 패치 간의 관계와 상호작용을 학습함. 이를 통해 CNN과는 다르게, ViT는 전체 이미지의 전역적인 특징을 학습할 수 있음
- MLP Head : Transformer Encoder의 출력이 나온 후, MLP Head에서 최종 분류 작업을 수행. 이는 기본적으로 Fully Connected Layer로 구성되어 있으며, 입력된 이미지가 어느 클래스(예: Bird, Ball, Car 등)에 해당하는지 결정함
* 신경망 유형 : RNN / CNN / Transformer
| RNN | CNN | Transformer | |
| 주된 용도 | 시계열 데이터, NLP, 음성 인식 | 컴퓨터 비전(이미지 인식, 객체 탐지) | NLP, 비전 트랜스포머로 이미지 처리에도 사용 |
| 작동 방식 | 이전 입력 상태를 메모리로 사용하여 예측 | 로컬 패턴(국소적 특징) 추출 | Self-Attention으로 전역적 특징 학습 |
| 특징 학습 | 시간적 의존성을 학습하여 시퀀셜 데이터 처리 | 고정된 입력 크기를 처리, 지역 정보 학습 | 전체 입력을 동시에 처리, 전역적 관계 학습 |
| 장기 의존성 처리 | LSTM, GRU로 해결 가능 | 어려움 있음 | 전역적인 의존성 학습 가능 |
| 연산 효율 | 시퀀셜 처리로 연산 속도가 느림 | 이미지 처리에서 연산 효율이 높음 | 모든 입력을 병렬 처리, 연산 자원이 더 필요 |
| 응용 분야 | NLP, 시계열 데이터, 음성 인식 | 컴퓨터 비전, 의료 영상 분석 | NLP, 컴퓨터 비전, 음성 인식, 번역 등 |
3) 부동소수점 숫자의 정밀도∙속도
- 32비트 부동소수점(FP32) : 정밀도가 높고, 연산 속도가 중간 정도. 정밀도는 높지만 연산 속도가 상대적으로 느림
- 16비트 부동소수점(FP16) : 속도가 빠르지만 정밀도는 32비트보다 낮음. 최근 딥러닝에서는 학습 속도 향상을 위해 자주 사용됨
- 8비트 부동소수점(FP8) : 반정밀도라고 하며, 매우 빠르지만 정밀도는 더 낮음. 실시간 작업에 유용할 수 있지만, 딥러닝에서 아직 널리 쓰이진 않음
4) YOLO Model
① 정의
- YOLO(You Only Look Once) : 객체 감지(Object Detection)에서 자주 사용되는 딥러닝 모델로, 입력 이미지에서 한 번에 객체를 감지하는 방식을 사용
② 모델 아키텍처
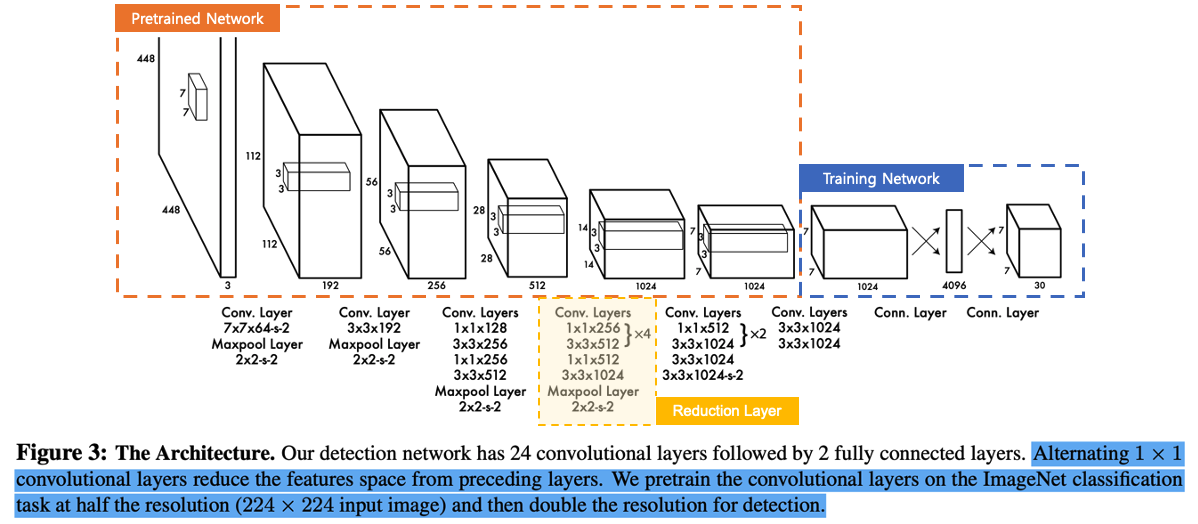
(1) Pretrained Network (사전 학습된 네트워크)
- YOLO는 사전 학습된 네트워크를 사용하여 기본적인 특징을 추출함. 이 네트워크는 주로 ImageNet과 같은 대규모 데이터셋에서 이미지 분류 작업을 위해 학습된 네트워크를 사용
- Conv Layer 7x7x64+2 : 첫 번째 컨볼루션 레이어는 커널 크기가 7x7이고, 채널 수는 64개. 이 레이어는 입력 이미지를 처리하여 448x448 크기의 피처 맵을 생성하고, 그 다음 MaxPool Layer(2x2 stride 2)를 통해 공간 차원을 절반으로 줄임
- 이 과정을 통해 공간 차원을 112x112로 줄이며, 뒤따라서 3x3 커널을 가진 여러 개의 컨볼루션 레이어가 계속 이어짐
(2) Convolutional Layers
- 3x3 Conv Layers : 이 네트워크는 24개의 컨볼루션 레이어로 이루어져 있음. 각 레이어는 3x3 커널을 사용하여 특징을 추출함. 이 컨볼루션 레이어는 입력 이미지에서 중요한 특징(특징 맵)을 추출하는 역할
- 이 과정에서 stride와 MaxPooling을 사용해 공간 차원이 계속 줄어들면서 중요한 정보만 남도록 만듦
- EX : 3x3x192, 3x3x512, 3x3x1024 등의 레이어가 쌓이면서 이미지의 공간 차원을 줄이고, 피처맵의 깊이를 늘림
(3) Alternating 1x1 Conv Layers
- 1x1 컨볼루션 레이어가 주기적으로 사용됨. 이 레이어는 차원 축소나 특정 채널 간의 상호작용을 학습할 때 유용
- 1x1x256과 같은 레이어는 채널 수를 조정하거나 중요한 특징만 남기도록 도움
- 1x1 컨볼루션은 다른 필터 크기를 가진 레이어와 교대로 적용되며, 특징 공간을 축소하는 역할
(4) Reduction Layer
- 네트워크 중간에서 Reduction Layer를 통해 공간 차원을 줄이고, 중요한 특징들만 남김. 이 과정에서 특징 맵의 해상도는 점점 낮아지고, 대신에 채널 수가 증가
- MaxPooling을 통해 특징 공간을 절반으로 줄이면서도 주요 특징들은 남김
(5) Training Network (학습 네트워크)
- Training Network는 YOLO의 후반부에서 Fully Connected Layer가 2개 이어진 구조. 마지막 컨볼루션 레이어를 거친 후, 나온 특징들을 4096개의 노드를 가진 완전 연결 레이어로 보내어 객체에 대한 정보를 학습함
- 마지막으로 30개 출력값을 갖는 레이어가 있는데, 여기서 각 객체의 클래스 정보, 바운딩 박스 정보(x, y 좌표, 너비, 높이) 등이 출력됨
(6) Output (결과)
- 최종적으로 이 모델은 Bounding Box와 클래스 정보를 포함한 30개의 출력을 생성. 이를 통해 입력 이미지에 있는 객체를 어디에 위치시키고, 어떤 종류의 객체인지를 예측
- 입력 해상도 224x224로 축소하여 학습하고, 출력 해상도는 448x448로 복구해 감지 작업을 진행
5) CPU / GPU / 클라우드 기반 GPU
| 처리장치 | |||
| CPU (Central Processing Unit, 중앙 처리 장치) | GPU (Graphics Processing Unit, 그래픽 처리 장치) | 클라우드 기반 GPU | |
| 처리 방식 | 순차처리: 한 번에 하나의 작업을 처리 | 병렬처리: 다수의 코어가 동시에 작업을 분배 | 병렬처리: 클라우드에서 대규모 병렬 작업을 지원 |
| 주요 사용 분야 | 일상적인 작업(웹 서핑, 문서 작업, 코딩 등) | 고사양 작업(그래픽 처리, 게임, 영상 편집, 3D 모델링, 딥러닝) | 딥러닝 학습, 대규모 데이터 처리, AI 모델 훈련 |
| 멀티 태스킹 | 여러 다른 작업을 동시에 처리할 수 있음 "멀티태스킹" | 동일 작업을 다수의 코어에서 동시에 수행 "병렬작업" | 동일 작업을 여러 서버에서 병렬로 처리 |
| 연산 능력 | 단일 코어당 높은 성능, 복잡한 계산에 유리 | 대량의 단순 계산에 최적화, 이미지 및 병렬 처리에 탁월 | 대규모 연산 능력: 수백에서 수천 개의 GPU 코어를 활용 |
| 성능 | 일반적인 작업에 최적화 | 그래픽 작업 및 병렬 연산에 최적화 | 확장성이 높아, 필요한 만큼 GPU 자원을 쉽게 확보 가능 |
| 확장성 | 확장성이 제한적(하드웨어 교체 필요) | 여러 GPU 장착 가능하나 물리적 제한 존재 | 필요에 따라 자원 확장이 가능(클라우드 서버 사용) |
| 비용 | 초기 비용이 비교적 저렴 | 고사양 GPU는 가격이 비쌈 | 사용한 자원만큼만 비용을 지불(유연한 비용 구조) |
| 유지 보수 | 로컬에서 관리(정기적인 업데이트 필요) | 그래픽 카드 유지 보수 필요 | 클라우드 업체가 유지 보수 담당(유지 보수 부담 없음) |
| 딥러닝 학습 | 느림. 딥러닝 모델 학습에는 적합하지 않음 | 고속 학습 가능하나, 대규모 학습에는 한계가 있음 | 대규모 데이터셋을 빠르게 학습할 수 있음 |
📙 내일 일정
- 자연어 처리(NLP) 모델

'TIL _Today I Learned > 2024.09' 카테고리의 다른 글
| [DAY 44] Deep Learning 실습 (1) | 2024.09.12 |
|---|---|
| [DAY 43] 자연어 처리(NLP) 모델 (0) | 2024.09.11 |
| [DAY 41] Deep Learning 실습 (0) | 2024.09.09 |
| [DAY 40] Deep Learning 실습 (0) | 2024.09.06 |
| [DAY 39] Deep Learning 실습 (0) | 2024.09.05 |



