[천재교육] 프로트 기반 빅데이터 서비스 개발자 양성 과정 9기
학습일 : 2024.08.23
📕 학습 목록
- 추천 시스템
- 최적화(코루틴, 멀티프로세싱/멀티스레딩)
📗 기억할 내용
1) 추천 시스템 (Recommender System)
① 정의
- 특정 사용자가 관심을 가질만한 정보(영화, 음악, 책, 뉴스, 이미지, 웹페이지 등)를 예측/추천하는 것
- 사용자에게 맞춤형 추천을 제공
- ex1 : 넷플릭스에서 시청한 영상과 유사한 영상을 추천
- ex2 : 온라인 마켓(쿠팡,...)에서 사용자가 과거에 구매하거나 관심을 가진 물건과 유사한 물건을 보여줌
② 알고리즘 종류
②-1 콘텐츠 기반 추천 시스템(Content-Based Recommender System)
- 사용자가 이전에 선호했던 아이템의 특징(콘텐츠)을 분석하고, 이와 유사한 특징을 가진 아이템을 추천
- 아이템의 메타데이터(예: 영화의 장르, 책의 주제, 제품의 특징 등)를 사용하여 추천을 수행

| 장점 | 단점 |
| - 개인화된 추천 : 사용자의 이전 행동•피드백을 바탕으로 개인화된 추천이 가능 - 다른 사용자 독립적 : 다른 사용자의 데이터 없이도 새로운 아이템을 추천할 수 있음 |
- 다양성 부족 : 사용자가 선호하는 것과 유사한 항목만 추천. 추천이 한정될 수 있음 - 특징 의존성 : 아이템의 특징이 얼마나 잘 정리되어 있는지에 따라 추천의 질이 달라짐 |
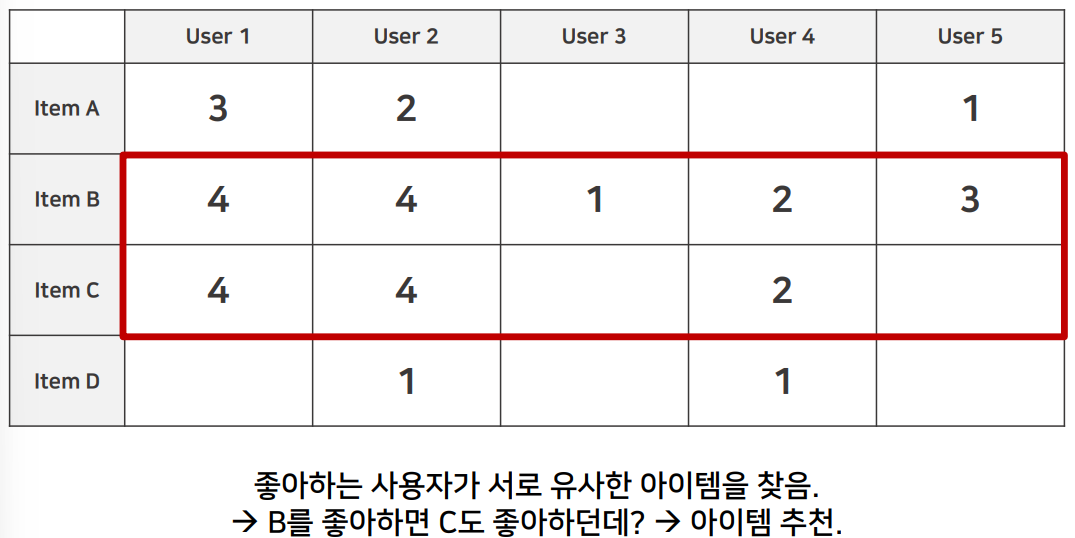
②-2 협업 필터링(Collaborative Filtering) 주로 사용!
- 사용자의 행동방식(사용자-사용자, 아이템-아이템 간의 상호작용)에 의존하여 추천
- 아이디어 : "비슷한 사용자들이 비슷한 아이템을 좋아할 것이다"
[협업 필터링의 두 가지 유형]
- 사용자 기반(User-based) : 사용자's 특징 - 다른 사용자들's 특징이 유사할 경우, 다른 사용자들이 좋아한 아이템을 추천
- 아이템 기반(Item-based) : 사용자가 이전에 좋아한 아이템과 유사한 아이템을 추천
- User-based

- Item-based
| 장점 | 단점 |
| - 개인화된 추천: 다른 사용자들의 행동 데이터를 활용하여 개인화된 추천이 가능 - 도메인 독립적: 콘텐츠의 구체적인 메타데이터 없이도 추천이 가능 |
- 콜드 스타트 : 새로운 사용자나 아이템에 대한 데이터가 부족할 경우 추천이 어려움 - 데이터 희소성 : 사용자가 많은 경우, 일부 아이템에 대한 평가가 부족할 수 있음. 이로 인해 추천의 정확도가 낮아질 수 있음 |
- 코사인 유사도(Cosine Similarity) : at 협업 필터링, 사용자 간의 유사도를 측정
[코사인 유사도]
- 두 벡터 간의 유사성을 측정하는 방법. 두 벡터 사이의 각도를 기반으로 유사도를 계산
- '-1 ~ 1' 사이의 값을 가짐
- 각도가 0에 가까울수록 두 벡터가 더 유사하다고 간주
- '1' : 두 벡터가 완전히 같은 방향을 가리키고 있음 (매우 유사함)
- '0' : 두 벡터가 서로 직교(orthogonal)함 (유사성이 전혀 없음)
- '-1' : 두 벡터가 완전히 반대 방향을 가리키고 있음 (매우 다름)


* A⋅B : 두 벡터 A, B의 내적(dot product)
* ||A||, ||B|| : 각각 벡터의 크기
- 벡터의 내적 : 두 벡터의 대응되는 원소들을 곱한 뒤 모두 더한 값
- 벡터의 크기 : 각 원소의 제곱을 모두 더한 뒤 제곱근을 취한 값

③ 교육분야에서 사용될 수 있는 추천 시스템
좋아하는 아이템?
➔ 좋아하는 문항?
➔ 맞힌 문항?
➔ 틀린 문항?
취향이 비슷한 사용자 찾기
➔ 틀린 문제가 유사한 학생 찾기
A를 좋아하면 B도 좋아하던데? → A를 구매한 고객에게 B아이템 추천.
➔ A문항을 틀린 사용자에게 B를 추천
2) 최적화 (Optimization)
- 프로그램을 효과적으로 동작하도록 하는 과정 "메모리, 연산시간 등을 줄이기"
- 반복 작업 • 빅데이터 처리에서 중요도 ↑
① 코루틴(Coroutine) : 파이썬에서 비동기 작업을 수행하기 위한 실행 단위를 키워드(async, await)를 사용하여 정의함
* I/O 작업 : 코드 입력 (input) / 코드 실행 후 결과 출력 (output)
| 구분 | 동기식(Synchronous) | 비동기식(Asynchronous) |
| 작업 진행 방식 | 순차적으로 작업이 진행됨 | 작업 순서에 의존적이지 않도록 실행됨 |
| 파이썬에서의 구현 | 일반 함수(def) 선언 및 이용 | 코루틴(async, await)을 이용 |
| 파이썬의 처리 방식 | 특정 코드가 실행되는 동안 다른 코드는 실행되지 않음 |
코루틴을 사용하여 여러 코드를 동시에 실행 가능 |
| 대표적인 패키지 | - | asyncio : 코루틴을 관리/실행할 수 있는 도구/함수를 제공 |
| 장점 | 코드가 이해하기 쉽고, 디버깅이 간편함 | I/O 작업 중에도 다른 작업을 동시에 처리할 수 있어 효율적임 |
| 단점 | I/O 작업이나 네트워크 요청과 같이 시간이 오래 걸리는 작업 중에는 전체 프로그램이 대기 상태가 될 수 있음 |
코드가 복잡해지고, 디버깅이 어려울 수 있음 |
| 사용 사례 | 간단한 스크립트나 순차적으로 실행되어야 하는 작업에 적합 |
웹 서버, 파일 입출력, 네트워크 요청 등 여러 작업을 동시에 처리해야 하는 경우에 적합 |
| 파이썬에서 사용 시 주의점 |
블로킹(blocking) 코드로 인해 성능 저하가 발생할 수 있음 |
모든 부분에 비동기 코드를 사용할 필요는 없음. 비동기 작업이 필요하지 않은 부분에서는 오히려 복잡도를 증가시킬 수 있음 |
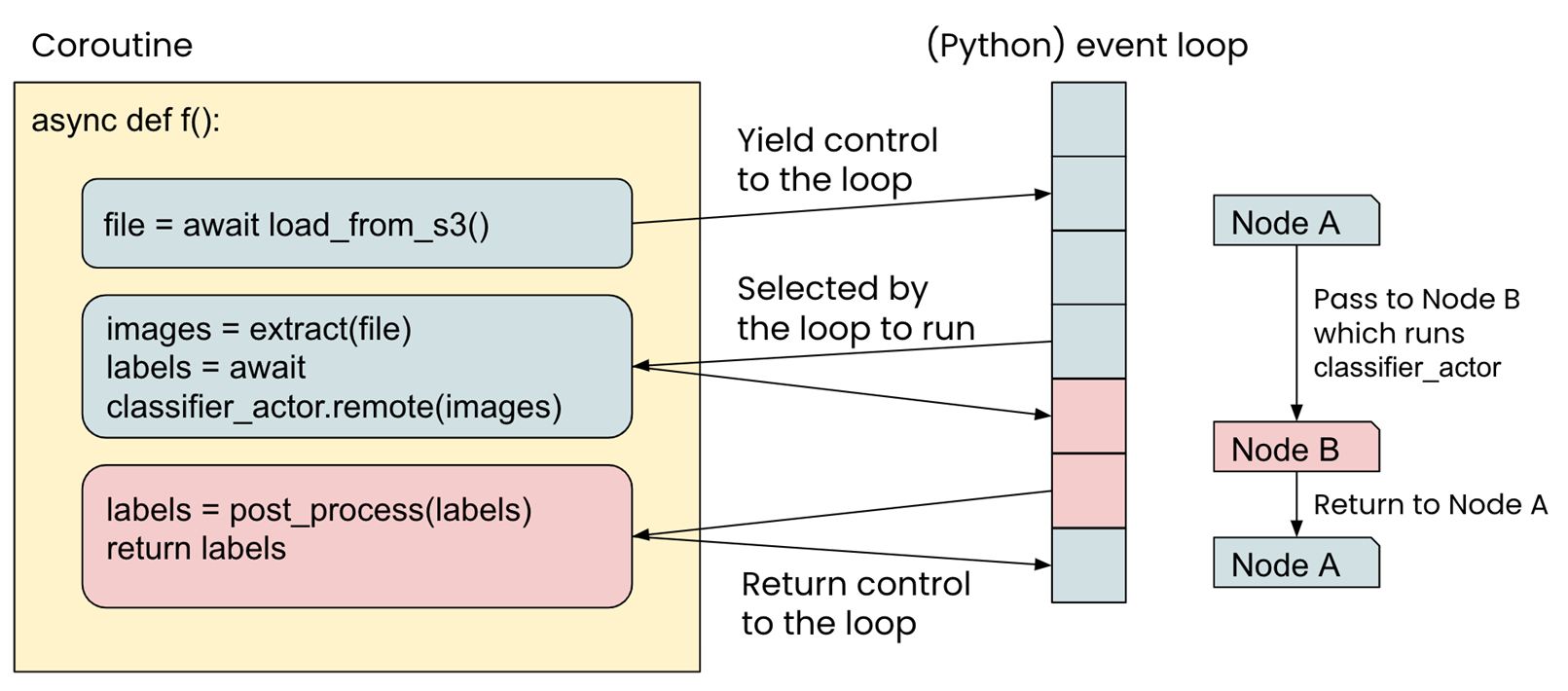
# [asyncio 패키지 함수 사용]
import asyncio
# 코루틴 정의
async def my_coroutine(): # my_coroutine 은 코루틴이 됨
print("Start work")
await asyncio.sleep(2) # 이 코루틴이 여기서 2초 동안 멈춤; 이때 다른 비동기 작업이 실행될 수 있음
print("Work finished")
# 코루틴 실행
asyncio.run(my_coroutine())
② 멀티프로세싱, 멀티스레딩
- 데드락 : 두 개 이상의 작업이 서로 상대방의 자원을 기다리면서 무한 대기 상태에 빠지는 문제
- 멀티프로세싱에서는 프로세스들이 독립적으로 실행되기 때문에 데드락이 발생할 가능성이 상대적으로 낮지만, 프로세스 간 통신에서 발생할 수 있음
- 멀티스레딩에서 자주 발생하는 문제로, 여러 스레드가 자원을 공유할 때 동기화가 제대로 이루어지지 않으면 데드락이 발생할 수 있음
| 구분 | 멀티프로세싱(Multiprocessing) | 멀티스레딩(Multithreading) |
| 정의 | - 여러 개의 프로세스를 사용하여 동시에 작업을 수행하는 방법 | - 하나의 프로세스 내에서 여러 스레드를 사용하여 동시에 작업을 수행하는 방법 |
| 프로세스 • 스레드 수 |
- 각각의 작업이 별도의 프로세스에서 실행됨 - 프로세스마다 독립된 메모리 공간을 가짐 |
- 여러 스레드가 하나의 프로세스 내에서 실행됨 - 스레드들은 동일한 메모리 공간을 공유함 |
| 메모리 사용 | - 각 프로세스가 독립된 메모리를 사용하므로 메모리 사용량이 큼 | - 스레드들이 메모리를 공유하므로 메모리 사용량이 적음 |
| 통신 방법 | - 프로세스 간 통신(IPC)을 사용하여 데이터를 주고받음 - ex: 파이프, 큐, 공유 메모리 등 |
- 스레드 간 통신은 공유 메모리와 변수로 이루어짐 |
| 병렬 처리 | - 진정한 병렬 처리가 가능함 - 멀티코어 CPU에서 프로세스들이 실제로 동시에 실행될 수 있음 |
- 스레드 간의 전환이 빠르지만, 진정한 병렬 처리 대신 동시 실행처럼 보일 수 있음 |
| 안정성 | - 프로세스 간의 메모리 독립성으로 인해 안정성이 높음 | - 공유 메모리로 인한 동기화 문제 발생 가능성이 높음 |
| 데드락 발생 | - 비교적 덜 발생함 - 프로세스 간에 독립성이 강해 교착 상태 발생 가능성이 낮음 |
- 자원 공유와 락(lock) 사용으로 인해 데드락이 발생할 가능성이 큼 |
| 스위칭 비용 | - 프로세스 간 전환이 비교적 비용이 큼 | - 스레드 간 전환이 프로세스보다 비용이 적음 |
| 사용 사례 | - CPU 집약적인 작업에 적합함. 예: 데이터 처리, 과학 계산 | I- /O 집약적인 작업에 적합함 - ex: 파일 읽기/쓰기, 네트워크 요청 처리 |
③ 벙렬 컴퓨팅(Parallel Computing)
- 여러 처리 장치(CPU 코어, GPU 등)를 동시에 사용하여 작업을 나누고 병렬로 처리하는 컴퓨팅 방식
* 병렬 처리란?
- 작업을 여러 작은 부분으로 나누고, 각각의 부분을 동시에 처리
- 작업의 전체 실행 시간을 단축할 수 있음
- 더 빠른 계산과 효율적인 리소스 사용 가
- 복잡한 계산을 빠르게 처리하거나, 대규모 데이터를 효율적으로 분석하기 위해 사용
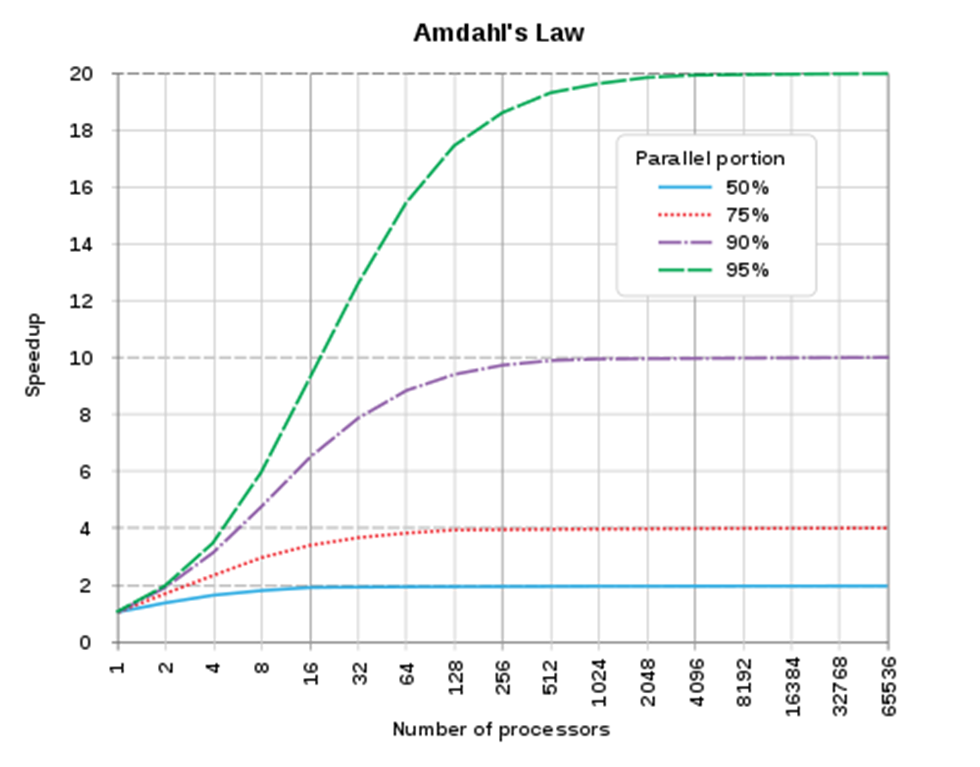
④ 암달의 법칙(Amdahl's law)
- 전체 작업의 P%에서 S배로 성능이 늘어나면, 시스템의최대 성능 향상은 1/{(1-P)+(P/S)) 임
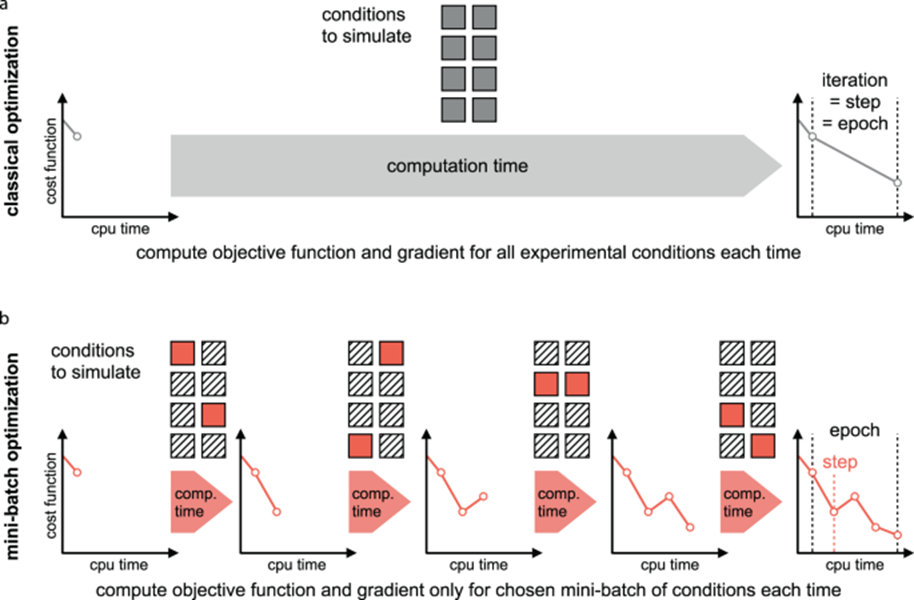
⑤ 미니배치(mini-batch) 최적화
- 배치(Batch) : 기계학습에 이용되는 데이터의 묶음
- Full-Batch : 학습 데이터를 모두 입력해 기계학습을 진행
- Mini-Batch : 일부 데이터로 소규모 학습을 여러 차례 진행
[아래 그림 설명]
- 전체 데이터를 여러 작은 부분(미니배치)으로 나누어, 각각의 미니배치에 대해 계산을 수행
- 즉, 데이터의 작은 부분만 사용하여 목표 함수를 계산하고, 그라디언트를 구한 뒤 파라미터를 업데이트
- 계산 시간을 크게 줄일 수 있으며, CPU 시간을 효율적으로 사용할 수 있음
- 여러 번에 걸쳐 작은 작업을 처리하는 방식으로, 비용 함수가 점진적으로 감소하는 모습을 보임
- 오른쪽 그래프에서는 여러 번의 작은 스텝(step)으로 비용 함수가 줄어들며, 에포크(epoch)가 여러 번 반복되는 것을 볼 수 있음
- 각 스텝에서는 적은 양의 계산이 이루어지지만, 전체적으로는 비용 함수가 꾸준히 감소하는 효과를 얻음
* 클래식 최적화 : 모든 데이터를 한 번에 처리하므로 계산 시간이 길지만, 큰 폭의 비용 함수 감소를 가져올 수 있음
* 미니배치 최적화 : 데이터를 여러 작은 부분으로 나누어 처리함으로써 계산 시간을 줄이고, 더욱 자주 파라미터를 업데이트하면서 점진적으로 비용 함수를 줄일 수 있음. 미니배치 최적화는 특히 대규모 데이터셋이나 고차원 문제에서 유용하며, 학습 속도를 높이고 자원을 더 효율적으로 사용할 수 있음
📙 내일 일정
- 머신러닝 실습

'TIL _Today I Learned > 2024.08' 카테고리의 다른 글
| [DAY 32] 머신러닝 모델의 검증 (0) | 2024.08.27 |
|---|---|
| [DAY 31] Machine Learning 실습 (0) | 2024.08.26 |
| [DAY 29] Machine Learning 실습 (0) | 2024.08.22 |
| [DAY 28] 회귀 / 차원축소 / 클러스터링 (0) | 2024.08.21 |
| [DAY 27] 분류 / 회귀 모델 (0) | 2024.08.20 |



